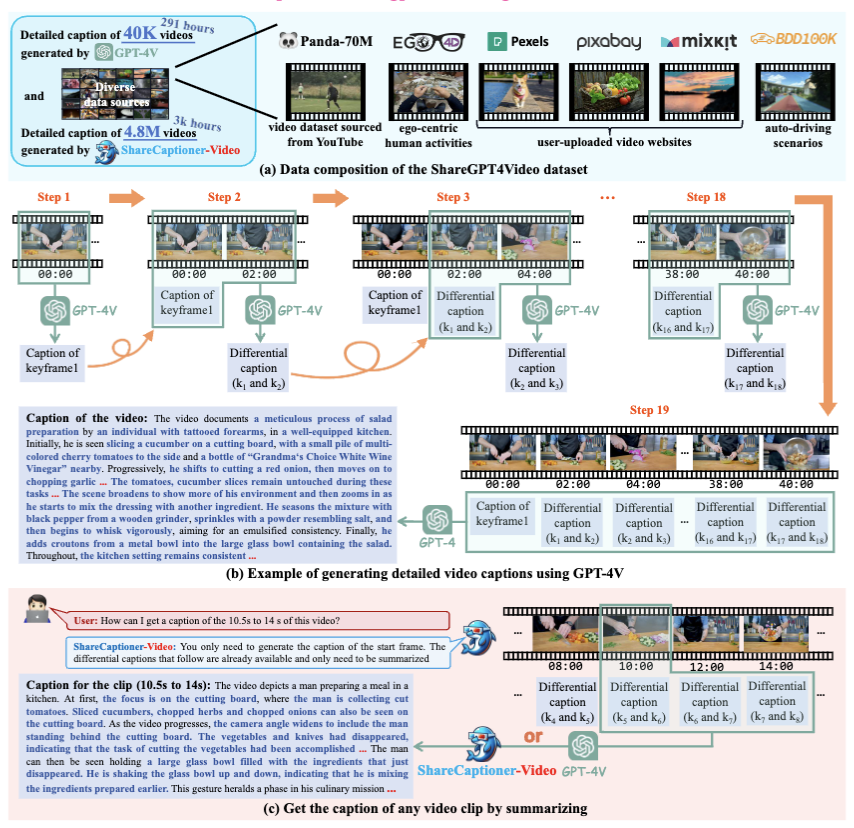
HedraRAG: Co-Optimizing Generation and Retrieval for Heterogeneous RAG Workflows
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | HedraRAG: Co-Optimizing Generation and Retrieval for Heterogeneous RAG Workflows |
| 作者 | Zhengding Hu, Vibha Murthy, Zaifeng Pan, Wanlu Li, Xiaoyi Fang, Yufei Ding, Yuke Wang |
| 会议 | SOSP 2025 (ACM Symposium on Operating Systems Principles) |
| 总结 | 从跨阶段、请求内和请求间三个角度解决异构RAG的计算效率问题 |
摘要
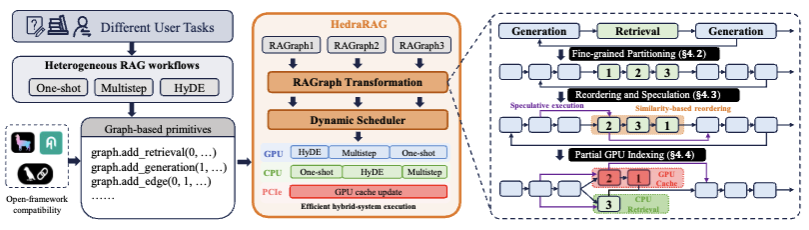
在本文中,我们识别并解决了服务异构 RAG 工作流时出现的系统级挑战,这些工作流以复杂的阶段和多样的请求模式为特征 。我们提出了 HedraRAG,这是一个基于 RAGraph 构建的新系统,RAGraph 是一种基于图的抽象,它揭示了跨阶段并行性、请求内相似性和请求间偏斜性(skewness)的优化机会 。这些机会通过图变换来表达,包括节点拆分、重排序、边添加和重连 。这些变换被动态地应用于跨并发请求的子图波前(wavefronts),并被调度到 CPU-GPU 流水线上 。在广泛工作流上的实验表明,HedraRAG 相比现有框架实现了超过 1.5 倍、最高达 5 倍的加速,为异构 RAG 工作负载服务提供了全面的解决方案 。
内容
1 引言 & 背景 & 相关工作
1.1 检索增强生成(RAG,Retrieval-Augmented Generation)
-
RAG 的优点:
- 访问外部知识但不用承担预训练的负担
- 减少幻觉
- 保护敏感数据的云端隐私
-
早期 RAG 的局限:
- 检索和生成的两阶段工作流
1.2 问题背景
-
早期两阶段工作流的相关研究: LangChain、FlashRAG 和基于 vLLM 的管道通过混合 CPU–GPU 设计将大语言模型(LLM)推理与 FAISS 等基于向量的检索组件集成在一起,以实现基本的检索增强生成(RAG)功能。
-
问题:
- RAG 逐渐复杂,呈现异质性。
- 请求的阶段数量、持续时间不同
- 不同的工作流模式
- 现有研究缺乏对 CPU-GPU 混合系统的并行利用。
- RAG 逐渐复杂,呈现异质性。
1.3 解决方案:HedraRAG
-
思路(从小到大):
- 跨阶段:流水线并行
- 请求内:重用和近似检索
- 跨请求:GPU 动态缓存检索
-
贡献:
- RAGraph:使用包括节点拆分、重排序、边添加和依赖重编等图转换操作提供工作流的统一视图,促进运行时优化。
- 三种技术:
- 细粒度的子阶段分区和动态批量处理(跨阶段)
- 具语义意识的重排序与推测执行(请求内)
- 部分GPU索引缓存结合异步更新(请求间)
1.4 RAG 的计算特性
- 检索:CPU上运行,因为大规模向量索引需要超出GPU支持的高内存容量。
- 生成:高度计算密集型,仅在GPU上运行。
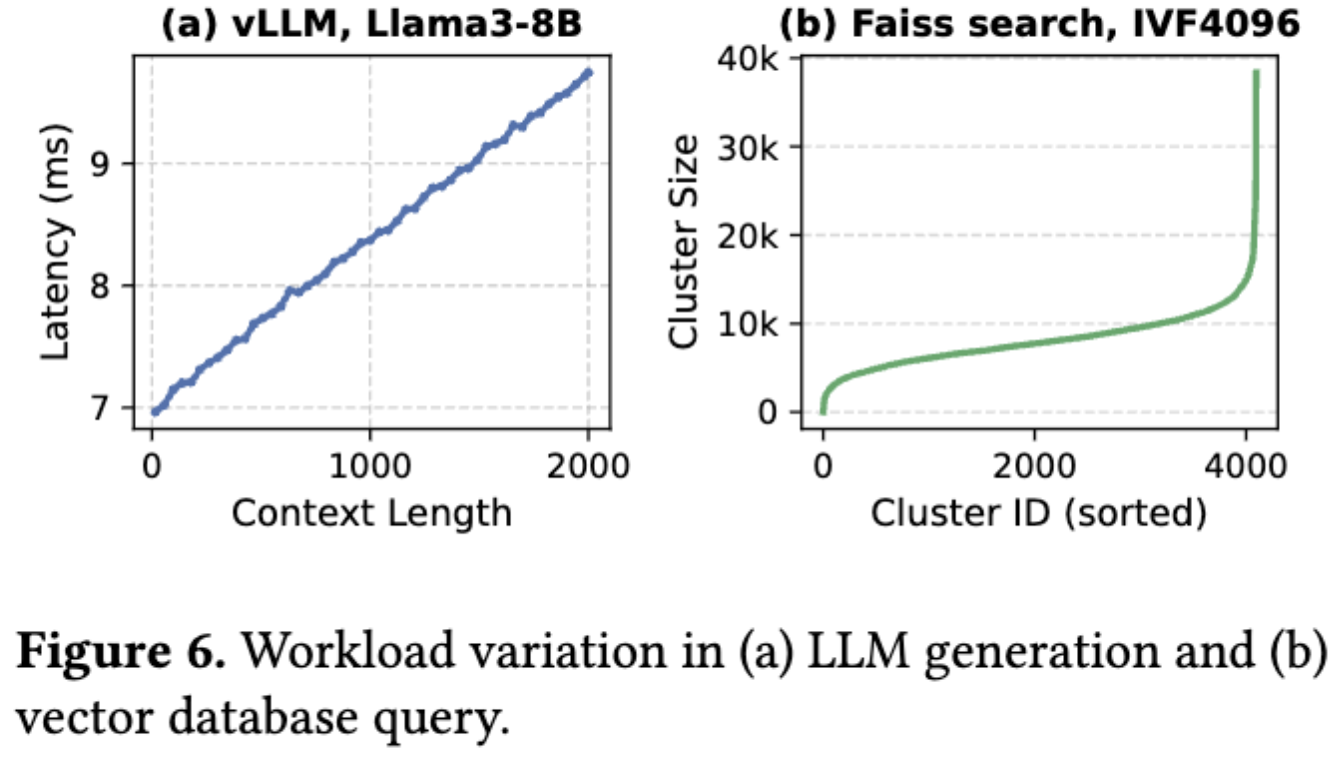
检索阶段:计算查询向量与存储向量之间的相似性,返回最接近的前 k 个匹配项。在 FAISS 中使用的倒排文件索引(IVF)通过类似 K-Means 的训练将向量划分为簇,由质心表示。在查询时,选择最接近的 n 个簇,并将搜索限制在这些区域,从而在准确性和速度之间进行权衡。
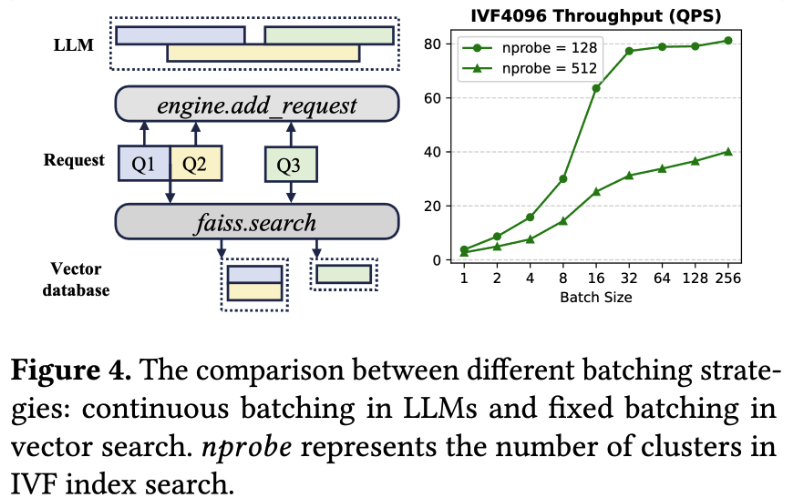
生成倾向于动态增加请求(左上),而检索倾向于积攒好大 Batch 后一次性请求(左下+右),存在偏好上的冲突。
1.5 相关工作
- 集成 RAG 工作流(没有运行时协调或共享优化):LlamaIndex、LangChain、FlashRAG
- 资源调度和分解部署:Chameleon、RAGO
- 重用文档前缀的加速生成:RAGCache、PromptCache、CacheBlend
- 早期终止检索、投机生成
2 动机
2.1 跨阶段:流水线并行
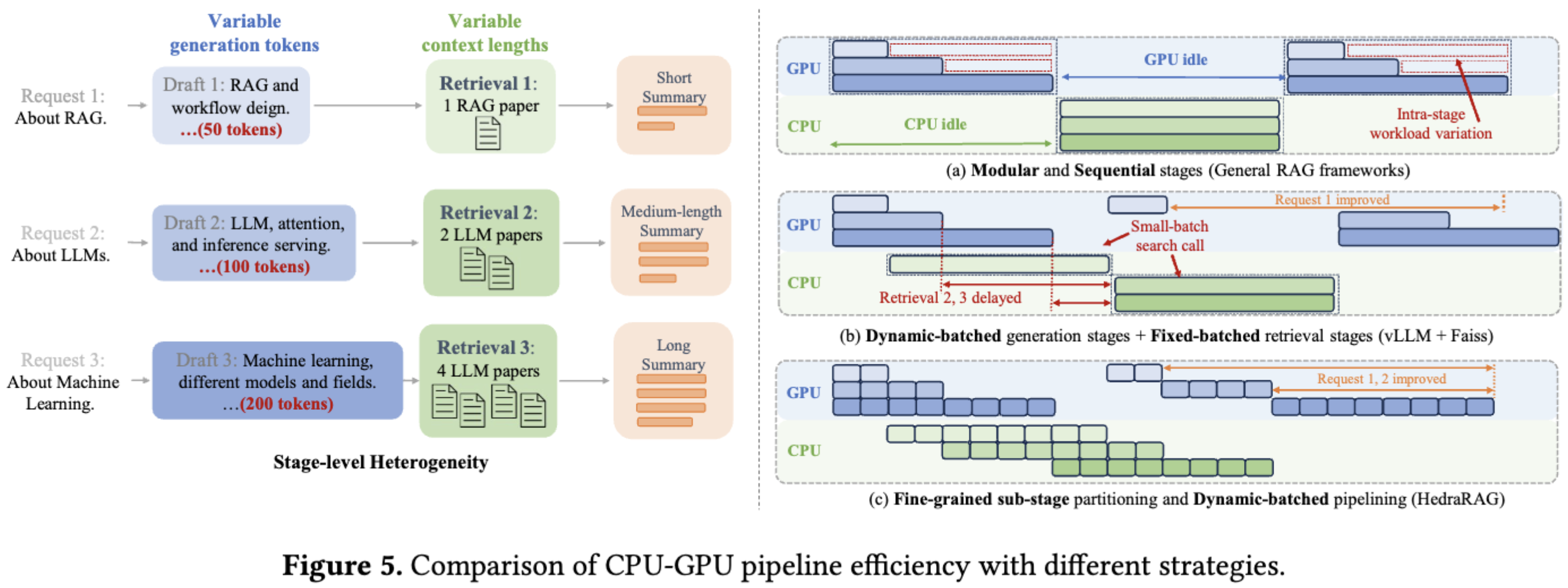
图中说明了粒度的粗细和并行策略对检索生成过程的影响:a 无法并行,b 由于 1 提前调用,所以 2、3 成批,c 中则增加了检索的结束和检查的频率,实现更高效的并行,所以目标是使得粒度变细,但是存在下面的问题:
通过等长阶段划分来实现平衡流水线化并不简单,因为生成阶段和检索阶段的工作负载是不平衡的。为了更好地理解不平衡的来源,作者分析了最小可调度单元的延迟特性:生成阶段的解码步骤和检索阶段的单簇搜索,并提出了一种动态、负载感知的对齐策略,根据实时工作负载调整子阶段边界。
2.2 请求内:重用和近似检索
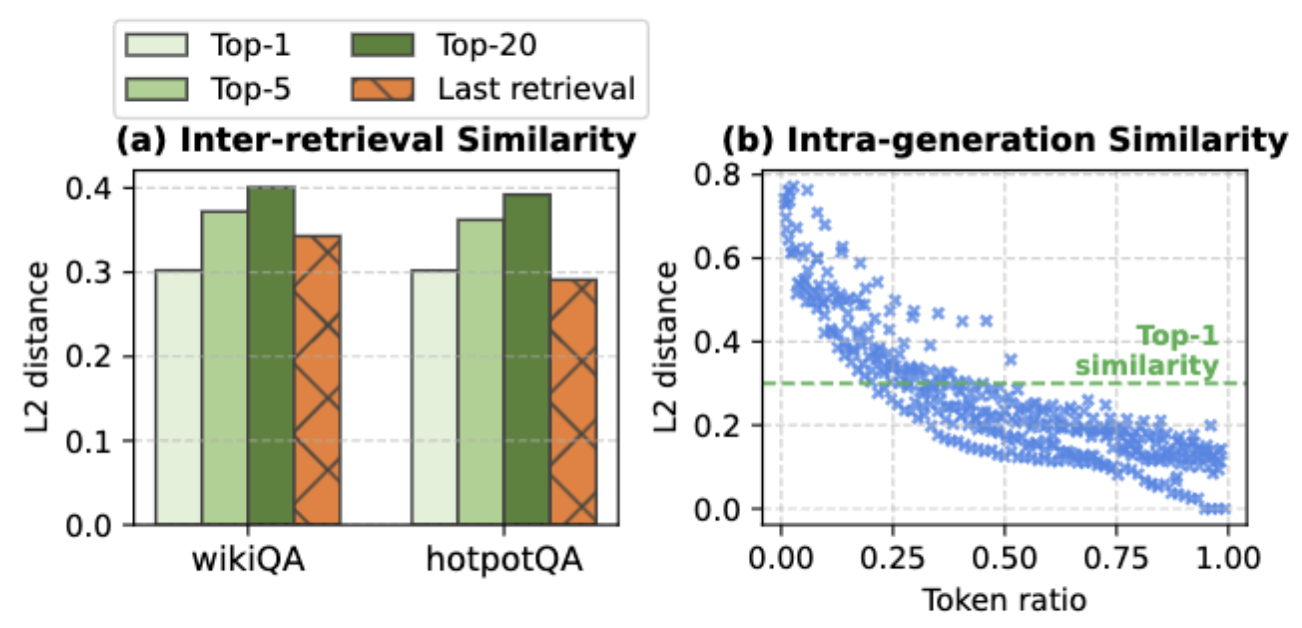
利用同一个请求内的阶段间会存在语义相似性。
- 检索相似性:图(a)
- 生成相似性:图(b)
传统的基于局部性的剪枝方法在高维嵌入空间中效果较差,于是作者引入了启发式、语义感知的策略:基于局部性的聚类重新排序和工作负载感知的推测执行。
2.3 跨请求:GPU 动态缓存检索
在大型的外部数据库中,检索开销远大于生成,可以将昂贵的向量相似性计算卸载到 GPU。
但是 LLM 推理消耗了大部分 GPU 内存,GPU 必须在需要时从 CPU 内存加载索引片段,这受限于PCIe的有限带宽。
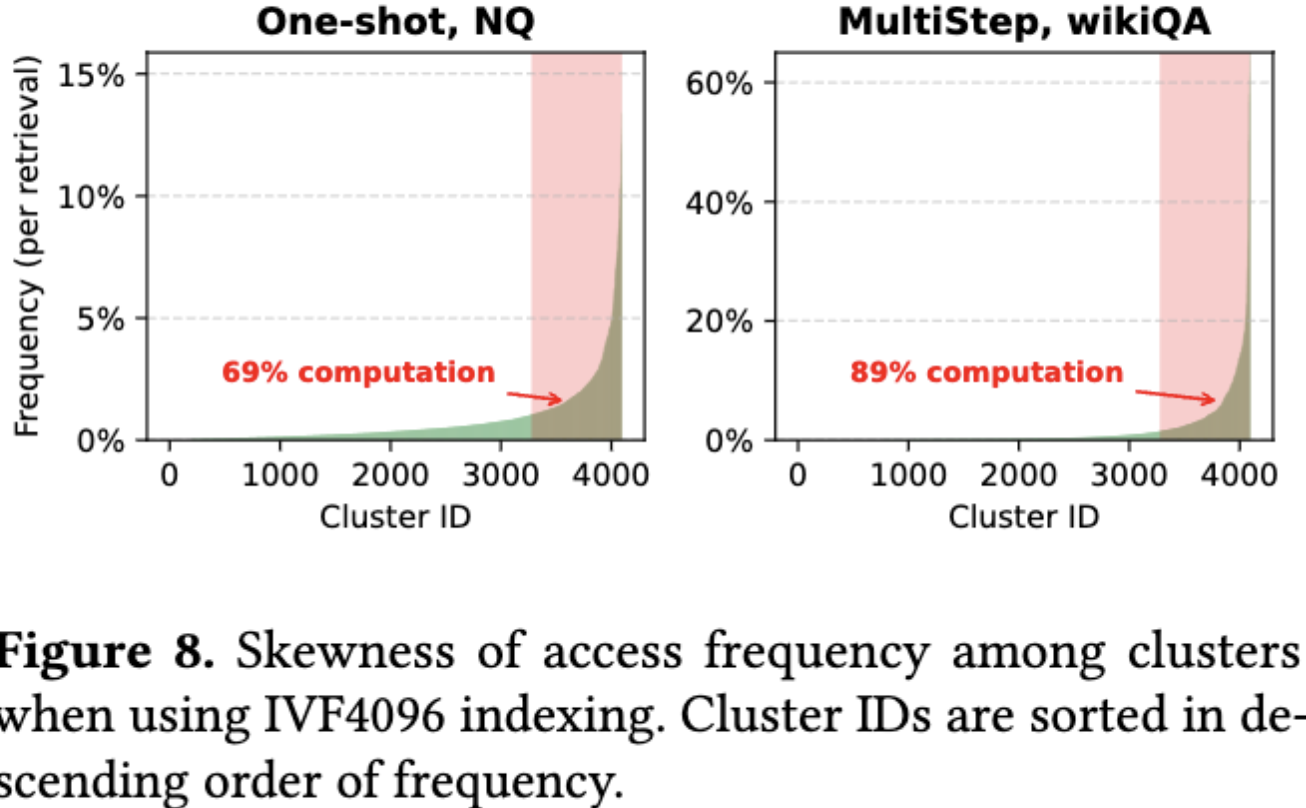
然后作者观察到了索引访问的倾斜性,实际的工作负载表现出对一小部分热点索引簇的集中访问,于是作者引入了一个部分 GPU 索引缓存,并采用异步更新。
3 方法:HedraRAG
3.1 RAGraph
该部分内容为文章的代码实现,重要程度一般,故省略。
3.2 跨阶段:流水线并行
前文已经解释过相关的动机和原理,这部分作者重点解释了如何进行阶段细粒度的划分。最简单的方法是固定生成步和检索簇数量,但是会导致对齐错误和负载不均衡。于是作者提出了动态时间预算方法。
动态时间预算方法: 该策略以检索为中心,从每个检索请求中逐步添加簇,直到达到最大时间预算 $mb$ ,然后该子阶段的执行时间就是该检索的工作时间。
以检索为中心意味着作者假定检索的时间变化要远大于生成的时间变化
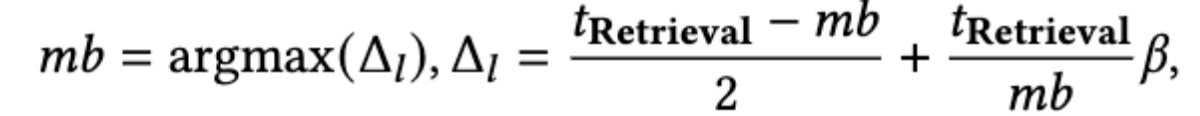
假设检索请求在所有子阶段中均匀到达,$\beta$ 表示请求调度和处理中间结果的 CPU 开销。$𝑡_{Retrieval}$ 表示检索阶段的平均时间,是在运行时测量的。
这里原文作者的公式应该是打错了,加号应该是减号,delta l 的含义是预期延迟改进,所以后项为增加的 CPU 切换开销,应该减去该部分。并且如果是加号的话 mb 应该直接取 0。
3.3 请求内:重用和近似检索
直接利用向量距离的相似性会导致维度灾难,即高维向量在向量空间中的分布变的稀疏,所以作者使用了语义相似性在 RAG 上下文中的分布规律。
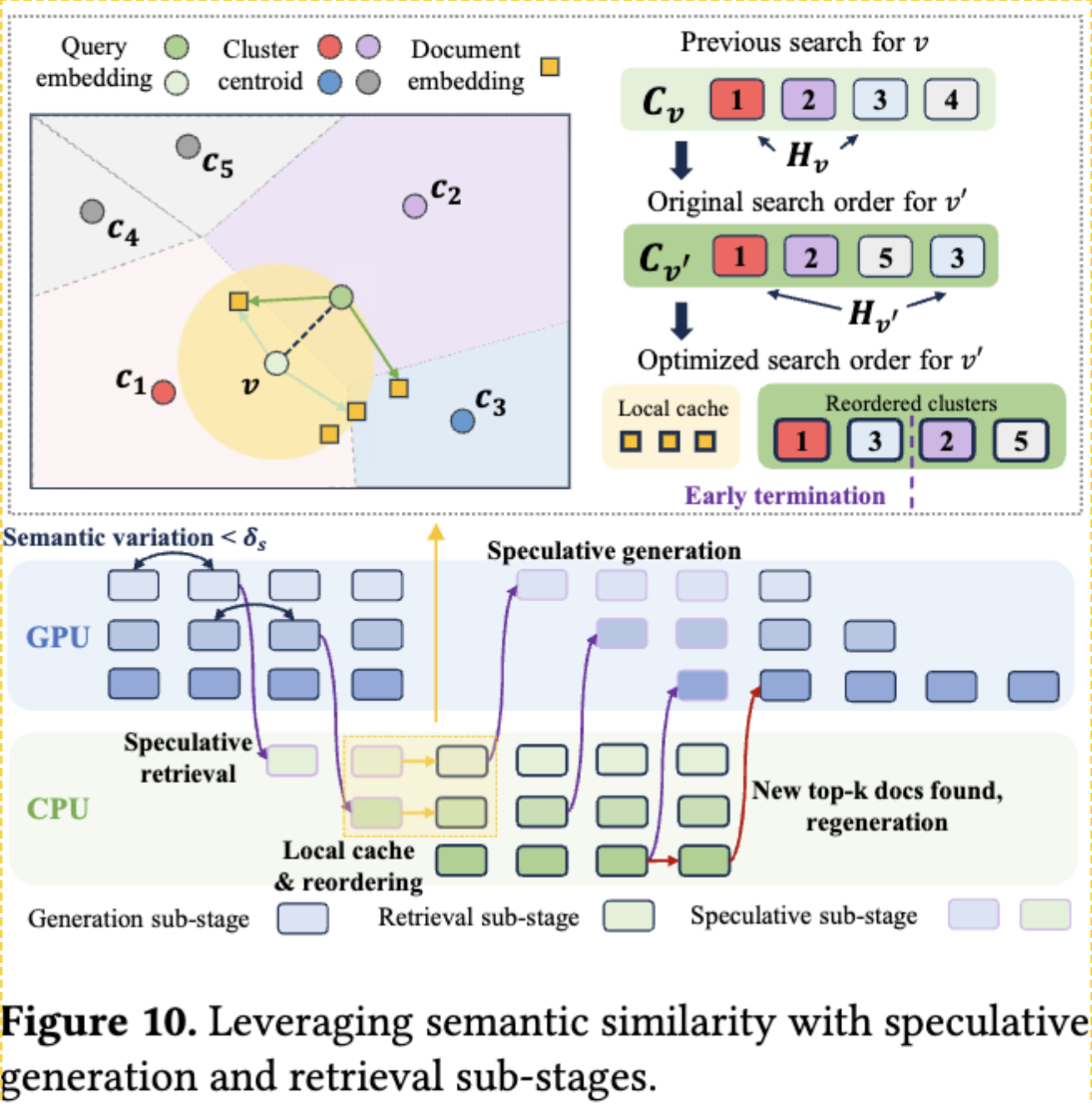
在 $v$ 的本地缓存中尝试搜索 $v’$:
- 首先搜索 $H_v\cap C’$
- 然后搜索 $(C-H_v)\cap C’$
- 最后搜索剩余的集群
除了上面的重排序缓存搜索,作者还使用了投机生成与投机检索:
- 投机生成: 当检索阶段之后跟着生成阶段时,可以使用小集群子集的部分搜索结果来启动推测性生成。如果失败则重新生成。
- 投机检索: 当一个生成阶段之后跟随一个检索阶段时,可以使用部分生成输出的嵌入来启动推测检索。如果失败则重新检索。
3.4 跨请求:GPU 动态缓存检索
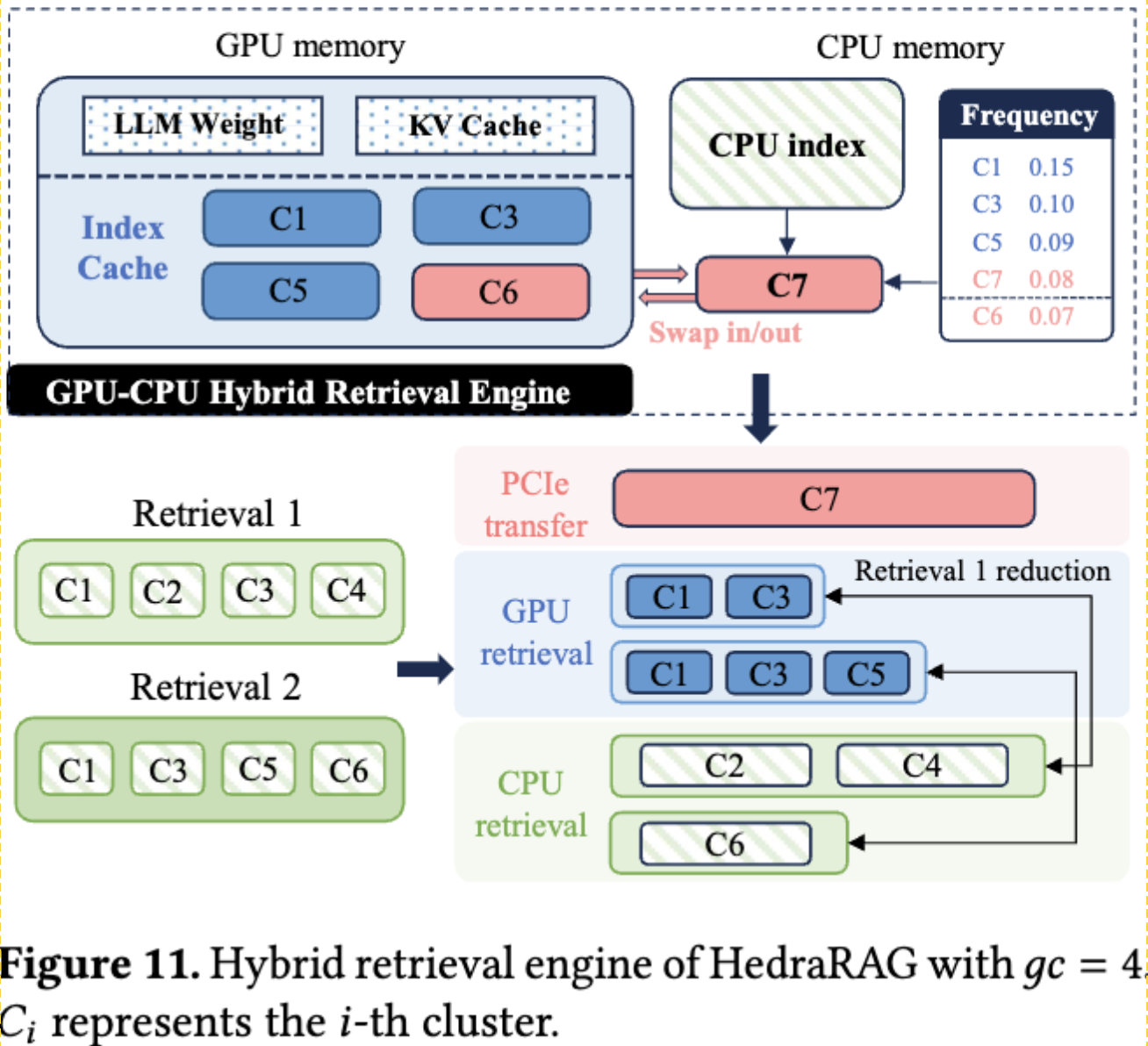
检索先从GPU内部检索,并按照使用频率在 CPU 和 GPU 间交换缓存的簇,使用频率的表按固定的时间间隔进行更新,在实践中一般是每 50 个子阶段。
LLM 权重与 KV 缓存的共存在 GPU 内部是一个权衡问题,所以作者定义了下面这样的一个函数以动态计算缓存大小:

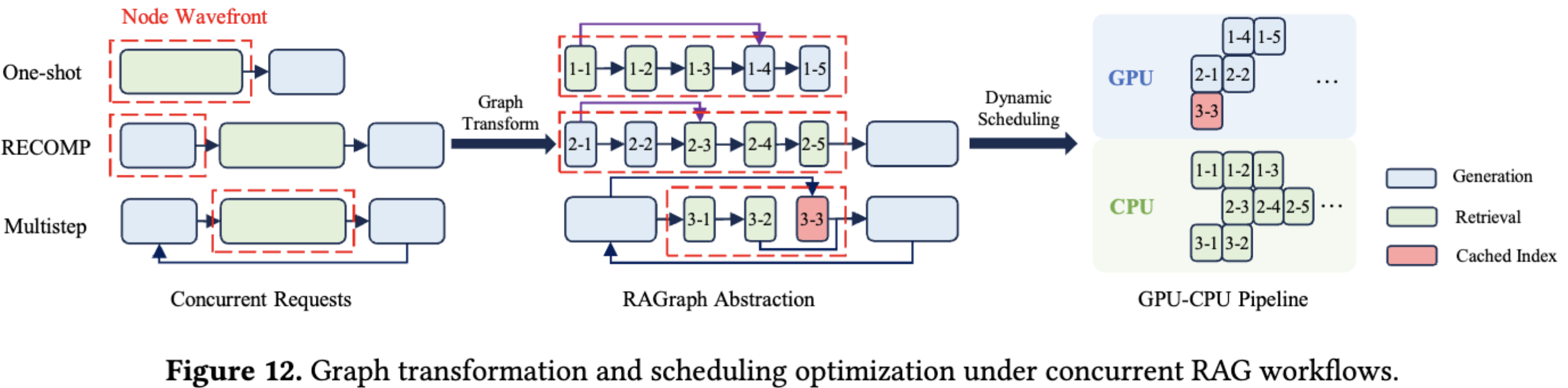
3.5 自适应图转换和调度
4 实验
4.1 实验环境
- 硬件: 向量搜索在 AMD EPYC 9534 64 核处理器上执行,LLM 生成则在带有 80 GB 内存的 NVIDIA H100 GPU 上进行。
- 模型: Llama 3.1–8B 为主,包含 Llama2-13B、OPT-30B
- 数据集: NaturalQuestions (NQ)、WikiMultiHopQA (wikiQA)、HotpotQA
- 基线:
- 异构 RAG 框架:LangChain、FlashRAG
- 投机执行:RaLMSpec、RAGCache
4.2 实验结果
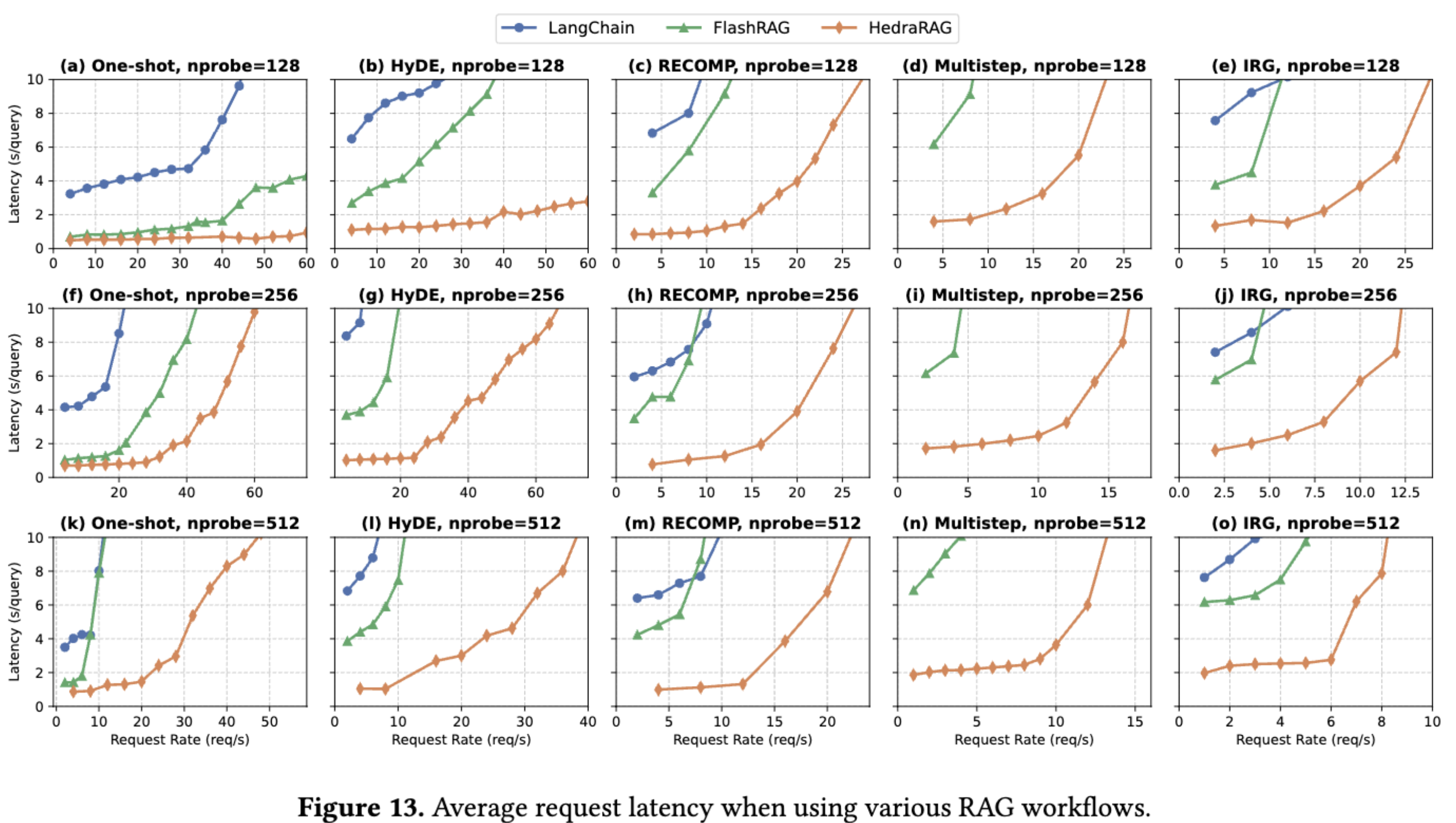
图中为 HedraRAG 与其他框架比较的延迟表现情况,在其他情景下的具体实验结果和分析请参阅原文,此处不一一列出。
HedraRAG: Co-Optimizing Generation and Retrieval for Heterogeneous RAG Workflows