Towards End-to-End Optimization of LLM-based Applications with Ayo
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | Towards End-to-End Optimization of LLM-based Applications with Ayo |
| 作者 | Xin Tan, Yinmin Jiang, Yitao Yang, Hong Xu |
| 机构 | The Chinese University of Hong Kong |
| 会议 | ASPLOS 2025 (ACM International Conference on Architectural Support for Programming Languages and Operating Systems) |
| 总结 | 用"原语拆分并优化以生成运行图"以及“上下层联合的运行时调度”实现LLM 应用工作流的端到端加速 |
摘要
基于大语言模型(LLM)的应用由 LLM 组件和非 LLM 组件共同组成,每一部分都会增加端到端的延迟。尽管在优化 LLM 推理方面已经做出了巨大努力,但端到端的工作流优化却一直被忽视。现有的框架采用基于任务模块的粗粒度编排,这种方式将优化限制在每个模块内部,导致了次优的调度决策。
我们提出了一种细粒度的端到端编排方法,它利用 任务原语(task primitives) 作为基本单元,并将每个查询的工作流表示为一个原语级的数据流图。这种方法显式地暴露了更大的设计空间,使得跨越不同模块原语的并行化和流水线优化成为可能,并增强了调度能力以提升应用级的性能。我们构建了 Ayo,这是一个实现了该方案的新型 LLM 应用编排框架。全面的实验表明,在各种流行的 LLM 应用中,Ayo 相比现有系统能够实现高达 2.09 倍的加速比。
内容
1 引言 & 相关工作
1.1 LLM 推理工作流
- 链式调用: 只能在模块内部进行性能优化,无法利用模块间的性能优化空间
- 原始级数据流图的编排: 获得全局最优的优化效果
1.2 Ayo 的组成
- 图优化器: 将查询解析为原语级别数据流图,并进行目标优化,生成高效的执行图。
- 运行时调度器: 利用两层调度,上层调度每个查询的执行图,下层由各个引擎调度器管理,批量处理来自查询执行图中相同引擎请求的原始操作,并考虑每个原始操作之间的关系,实现应用程序感知的调度。
1.3 相关工作
- LLM 推理优化:内核加速、请求调度、模型并行化、语义缓存、KV缓存管理、KV缓存重用、高级解码算法、预填充和解码分离
- LLM 应用框架:多 LLM 调用框架、AI Agent 框架、
- 数据分析系统:使用基于图的依赖分析来增强大数据分析工作负载的分布式任务执行。Ayo利用这些技术进行图优化。
在这里,作者强调 Ayo 的主要贡献是把这些工作作为组件集成起来,而不是发明了这些关键技术。
还有一点比较诡异的是,该篇文章中,相关工作是作为第 9 个 Section 出现在文章中的,而不是常规的出现在引言后面。
2 背景 & 动机
2.1 基于 LLM 的应用
-
LLM 推理的两个阶段:
- 预填充: 处理所有输入 Token(指令、上下文等)来生成第一个输出 Token,并且显然是计算密集型的。
- 解码: 基于KV缓存迭代生成其余输出,并且是内存限制的,因为在每次迭代中只需要处理上一次迭代的新 Token。
-
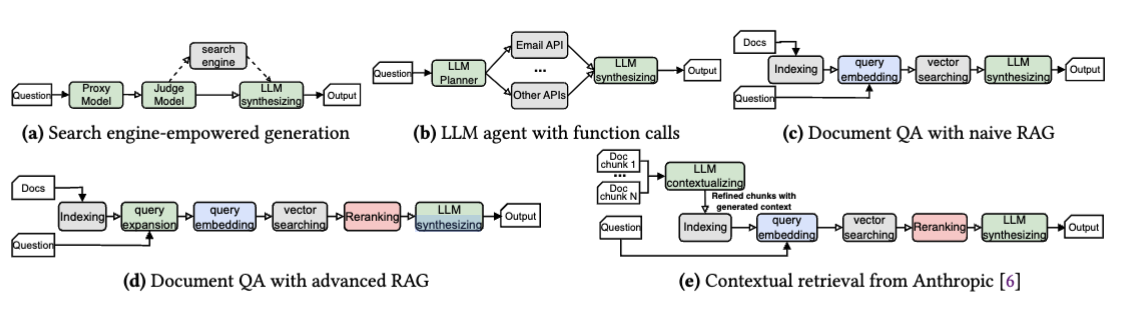
5 种基于 LLM 应用的工作流:
a. 搜索引擎辅助生成
b. LLM Agent
c. naive RAG
d. advanced FAG
e. 上下文检索工作流:LLM使用文档中的额外内容为每个文档片段生成上下文摘要。这些摘要被添加到片段前面,确保每个片段在独立处理时与原始文档保持连贯。
作者调查了 Github 的许多项目,证明了大部分项符合上述 5 种工作流中的一种
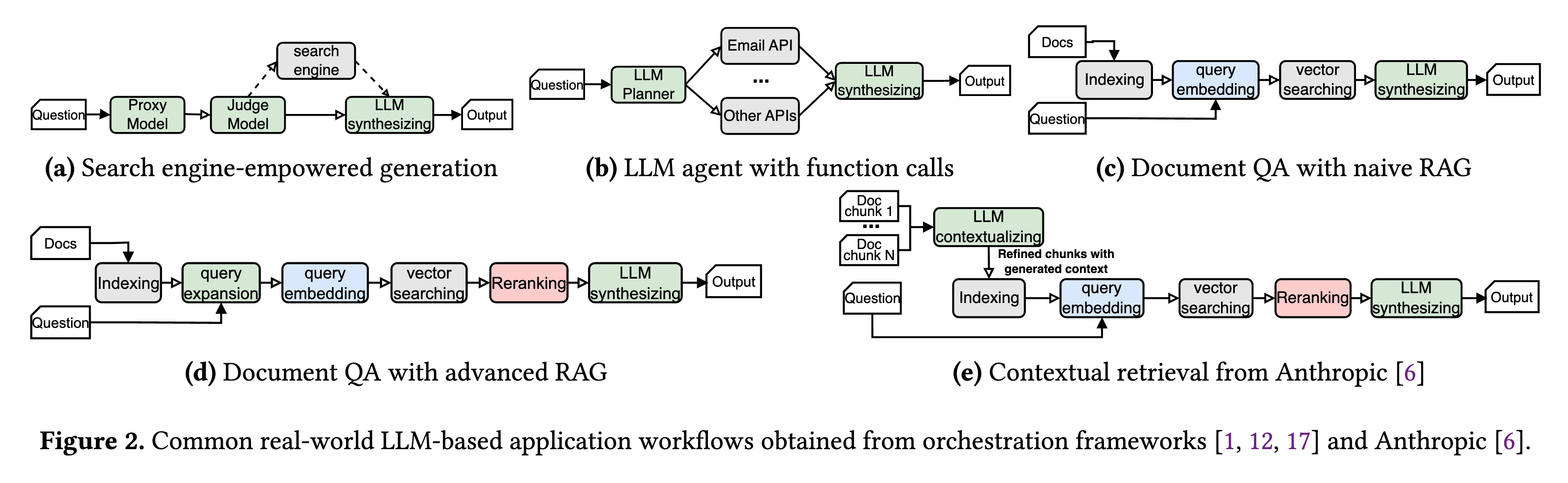
2.2 LLM 应用的细粒度编排
问题:目前存在的代理模块理所当然地使用模块级的编排方式,所以错过了子任务间进行端到端优化的机会。
三个子图的含义如下:
- a 为传统的模块级编排方式
- b 将每个模块分解为基本编排单元(即图中的节点)的细粒度原语,并且这些原语之间的依赖关系在数据流图中明确捕获。
- c 为优化执行图,是 b 的流水线并行版本。预填充-解码-嵌入-搜索的流程是可以拆分并行的,所以图中利用对 Query Expansion 的原语级拆分实现了流水线的并行。
2.3 应用感知调度与执行
作者在这里说了一句关键的话:The request-level optimization of the backend execution engines, which is a mismatch with the application-level performance that the user perceives.
意思是在端到端的请求中,负责每个模块或原语部分的引擎并不关心整体的“应用级表现”,只是关心自己的“请求级优化”,换言之,所有的执行引擎都在争取达到自己的最优,但是这并不一定是全局最优的决策方式。
由这个结论我们可以意识到应用一个整合框架以整合所有的组件是必要的。
3 设计概览
该段涉及到了工程实现中的 API 约定等内容,由于我们侧重理解原理,所以我会略过与理论无关的内容
3.1 Ayo 处理请求的流程
- Workflow Template(工作流模版):这是开发者写死的逻辑,比如:先检索,再生成。
- p-graph (Primitive-level Graph,原语图):关键部分,当一个具体的请求(Query)进来后,Ayo 会根据模版生成一个动态的图。(模版是死的,p-graph 是活的。比如模版里写的是“LLM 生成”,在 p-graph 里可能会根据输入被拆解成 3 个具体的“Partial Prefilling”节点。)
- e-graph (Execution Graph,执行图):这是经过第四章“图优化器”魔改后的图。加了并行、流水线后的最终执行计划。
后面的优化算法,本质上就是把 p-graph 变成 e-graph 的过程。
3.2 Ayo 的架构
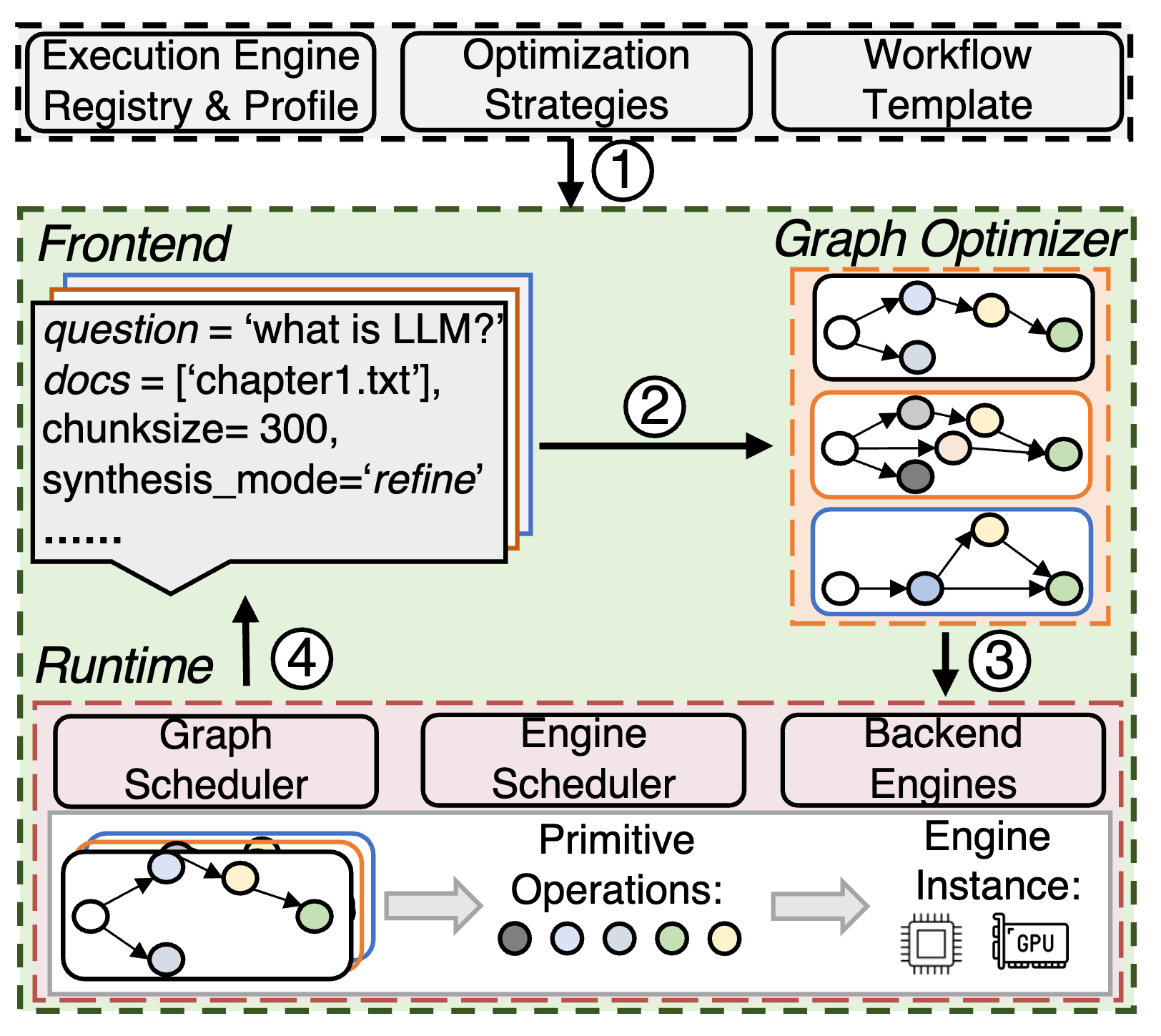
Ayo 如何在应用层捕获全局依赖?
在 Frontend 部分,Ayo 通过 Graph Optimizer 建立 p-graph 来实现对全局依赖的捕获,每个节点(执行单元)都包含了与全局相关的元数据。
4 图优化器
4.1 原语(Primitives)
一个原语可以对应注册执行引擎中的标准操作功能(例如,嵌入创建在嵌入引擎中或重排序中的上下文排名),或者表示一个细粒度分解的操作。此外,原语还可以是控制流操作,如聚合或条件分支(即聚合和条件)。
每个原语包括一个元数据配置文件,详细说明其输入、输出、父节点和子节点,形成图形构建的基础。该配置文件还包含关键属性,如DNN的批量大小或LLM的提示,以及目标执行引擎。
4.2 优化
优化的目的是在分布式执行中最大化并行性,优化器通过一套基于规则的静态优化,识别原始并行性(并行化)和流水线并行性(流水线化)的机会。
4.2.1 第一步:依赖关系剪枝
消除不必要的依赖关系,并通过检查每个任务基本操作的输入与其当前上游基本操作来识别可以并发执行的独立数据流分支。
冗余边被修剪,确保剩余的边仅表示数据依赖关系,这会使某些任务基本操作脱离原始依赖结构。
4.2.2 第二步:计算密集原语的流水线化
对于那些处理数据超出引擎最大高效批处理大小(即吞吐量不再增加的大小)的可批处理原语,它们会被分解成多个阶段,每个阶段处理一个子微批,并与下游的可批处理原语流水线连接。
虽然更激进的划分可能会增加流水线程度,但找到最优划分大小需要大量时间,所以只在原语的输入大小达到最大高效批处理大小时显式地将其分割成多个阶段。
4.2.3 第三步:LLM 关键属性 —— 因果预填充
允许 LLM 的预填充被分割成提前可用部分(如提示词)和依赖部分(如 RAG 的知识),使部分预填充与先前的原语并行化。
4.2.4 第四步:LLM 关键属性 —— 流式解码输出
LLM 解码的部分输出可以预先作为输入传递给下游原语,创造额外的流水线机会。
LLM调用必须被标注为可分割的,表明其输出可以语义上划分为不同的部分。相应的解析器会监控解码过程的逐步、结构化输出(例如JSON),一旦部分解码完成,就立即提取并转发给后续处理单元。
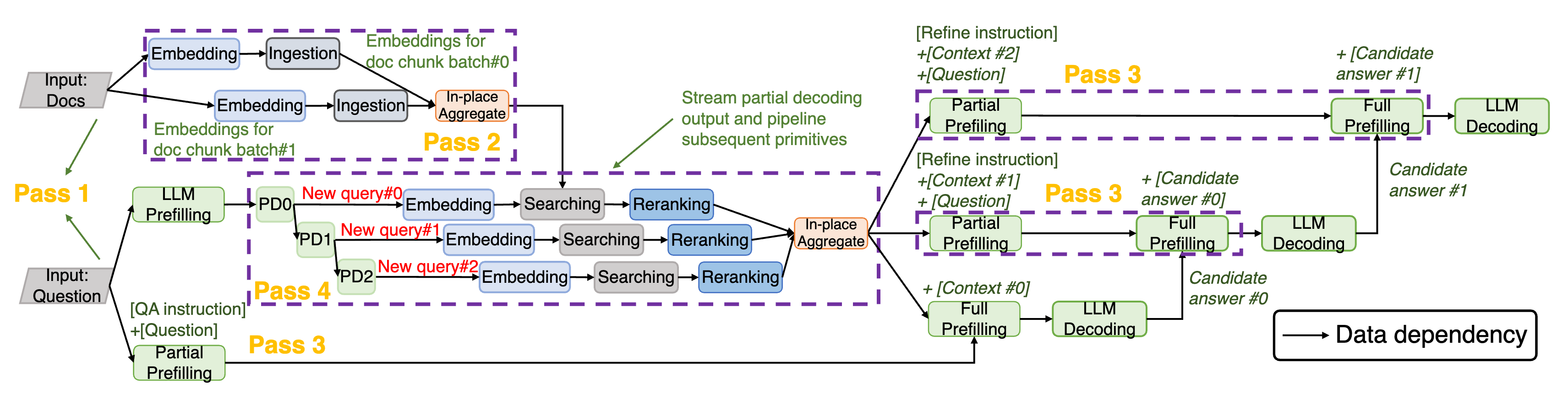
(上图是一个优化的例子)
5 运行时调度
5.1 上层:图调度器
职责: 图调度器评估节点的入度(等待完成的依赖数量),并在入度达到零时将节点分派给适当的引擎调度器。
特点: 图调度器分派的是节点本身而不是其关联的请求,换言之,执行引擎可以获得节点相关的元数据,保证了框架的全局信息的传递。
5.2 下层: 引擎调度器
职责: 管理所有引擎实例并调度批任务到引擎上。
盲目批处理可能导致提前调度没什么用处的节点(拓扑深度低的节点),所以作者提出了拓扑感知批处理,优势如下:
- 对于单个查询,深度信息自然捕获了不同原语之间的依赖关系,使得可以根据每个原语中的固有请求相关性直接调整调度偏好
- 虽然由于实际执行中的不可预测延迟,深度信息可能无法准确确定关键路径,但它可以指导查询中原语的优先级排序,从而在多个查询中促进资源的有效利用。
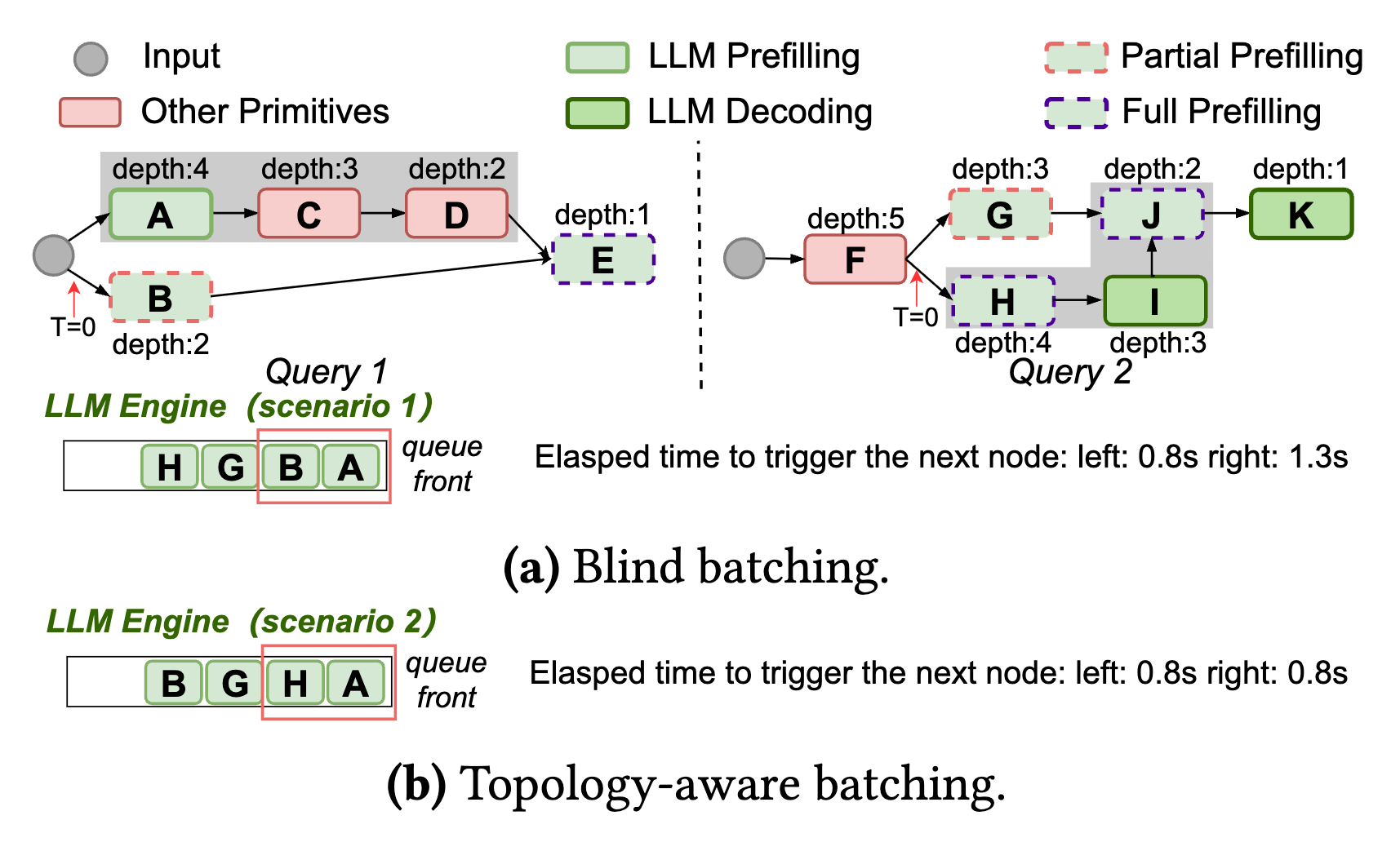
6 实现
作者利用了几个现有的库:
- Ray 用于分布式调度和执行;
- LlamaIndex 用于预处理任务,如文本分块和HTML/PDF解析;
- postgresql 作为默认数据库;
- pgvector 作为向量搜索引擎;
- Google 自定义搜索作为搜索引擎,支持单个和批量请求;
- vLLM 作为 LLM 服务引擎,作者还对其进行了修改,以支持表2中的部分预填充和完全预填充。
项目开源于: https://github.com/NetX-lab/Ayo
7 实验
7.1 实验环境
实验在一个分布式的异构计算集群中进行,涵盖了不同规模的模型和硬件配置:
-
硬件配置:
- 网络:服务器之间拥有 100 Gbps 的带宽 。
- 非 LLM 引擎(如 Embedding 模型):部署在单个 NVIDIA 3090 (24GB) GPU 上 。
- LLM 引擎:
- gemma-2-2B 和 llama-2-7B:部署在 1 个 NVIDIA 3090 GPU 上 。
- llama-2-13B:部署在 2 个 NVIDIA 3090 GPU 上 。
- llama-30B:部署在 2 个 NVIDIA A800 (80GB) GPU 上 。
-
对比基线 (Baselines):
- LlamaDist:基于 Ray 的 LlamaIndex 分布式实现,采用粗粒度的模块级链式编排,模块间顺序执行 。
- LlamaDistPC (Parallel & Cache-reuse):LlamaDist 的增强版,手动并行化了独立模块,并引入了 Prefix Caching(前缀缓存)来复用部分指令的 KV Cache 。
- AutoGen:流行的多 Agent 框架,通过预定义的图进行 Agent 间通信 。
-
调度策略对比:
- PO (Per-Invocation oriented):面向单次调用优化,优先考虑每个请求包的延迟 。
- TO (Throughput oriented):面向吞吐量优化,使用动态批处理(Dynamic batching)和预设的最大 Batch Size,忽略请求间的关系 。
7.2 端到端性能表现
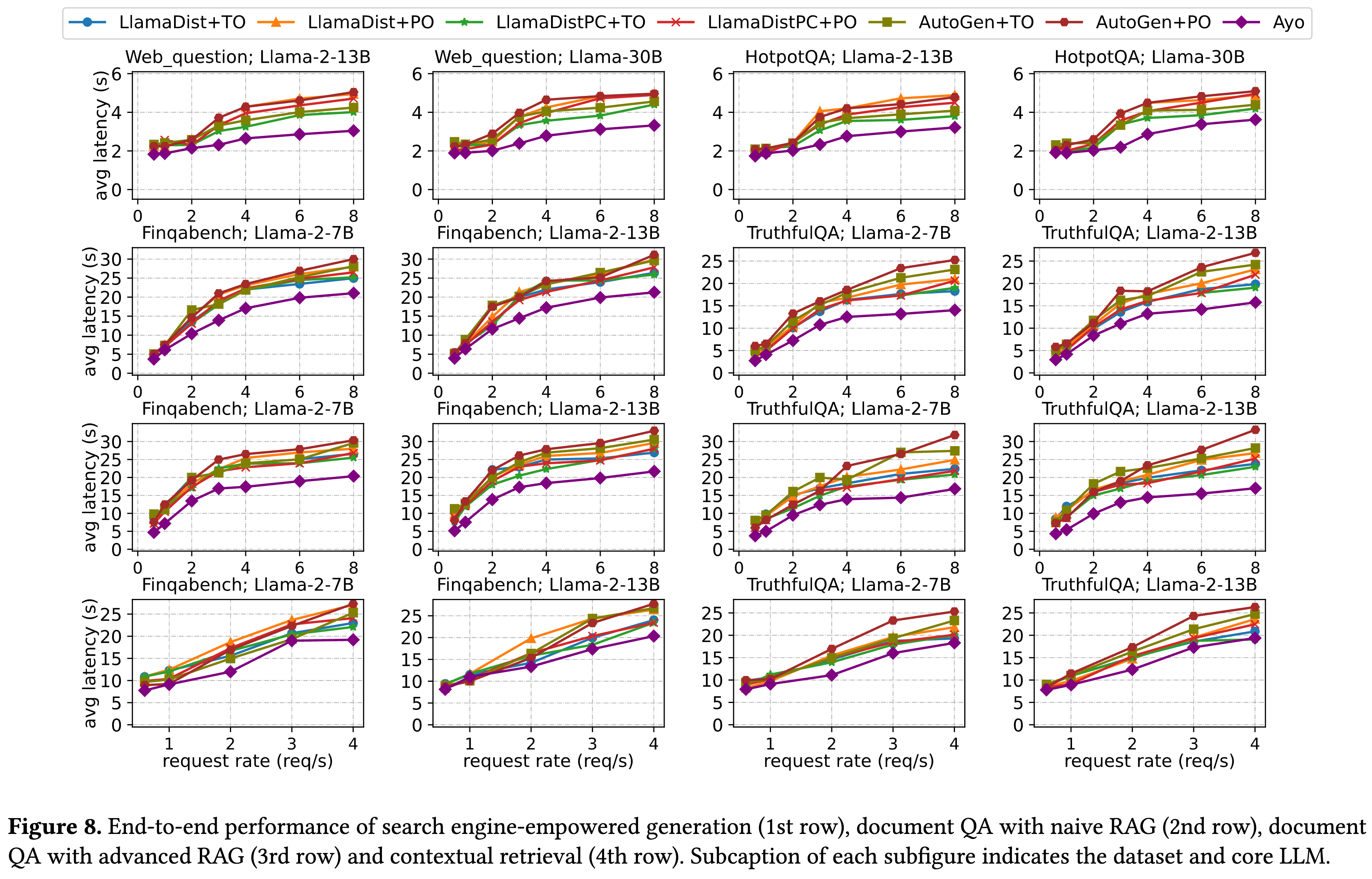
结合 Figure 8,论文在四种不同的应用工作流中评估了 Ayo 的性能。Ayo(图中紫色线条)在所有场景下均表现出最低的延迟。
-
场景 1:搜索引擎增强生成 (Search engine-empowered generation)
- 对应图表:Figure 8 第一行 。
- 表现:Ayo 相比其他六种基线方案,最高实现了 1.79 倍 的加速 。
- 原因:Ayo 利用了并行化技术,对 Judge Model(裁判模型)和 Core LLM(核心模型)的指令与问题进行了 Partial Prefilling(部分预填充),并有效协调了不同引擎的批处理 。而 LlamaDist 是顺序执行,PO 策略在高并发下排队时间过长 。
-
场景 2:朴素 RAG 文档问答 (Document QA with naive RAG)
- 对应图表:Figure 8 第二行 。
- 表现:Ayo 在低请求率下最高加速 1.62 倍,高请求率下加速 1.67 倍 。
- 原因:Ayo 通过 Pipelining(流水线) 拆分了大的 Embedding 任务,并利用并行化处理部分预填充 。同时,拓扑感知批处理 捕捉了请求间的依赖关系,避免了像 PO 和 TO 那样因忽视依赖导致的批处理效率低下 。
-
场景 3:高级 RAG 文档问答 (Document QA with advanced RAG)
- 对应图表:Figure 8 第三行 。
- 表现:Ayo 的优势最明显,最高实现了 2.09 倍 的加速 。
- 原因:该场景最复杂,Ayo 充分利用了 Query Expansion(查询扩展) 带来的并行分支机会,以及将解码过程拆分以进行流水线传输 。相比之下,即使是增强版的 LlamaDistPC 也无法利用这种细粒度的并行和流水线机会 。
-
场景 4:上下文检索 (Contextual retrieval)
- 对应图表:Figure 8 第四行 。
- 表现:实现了 1.06 倍到 1.59 倍 的加速 。
- 原因:尽管该工作流中有大量耗时的上下文处理步骤难以进行图层面的优化,Ayo 的应用感知调度和其他组件的图优化依然带来了显著提升 。
7.3 共置应用性能
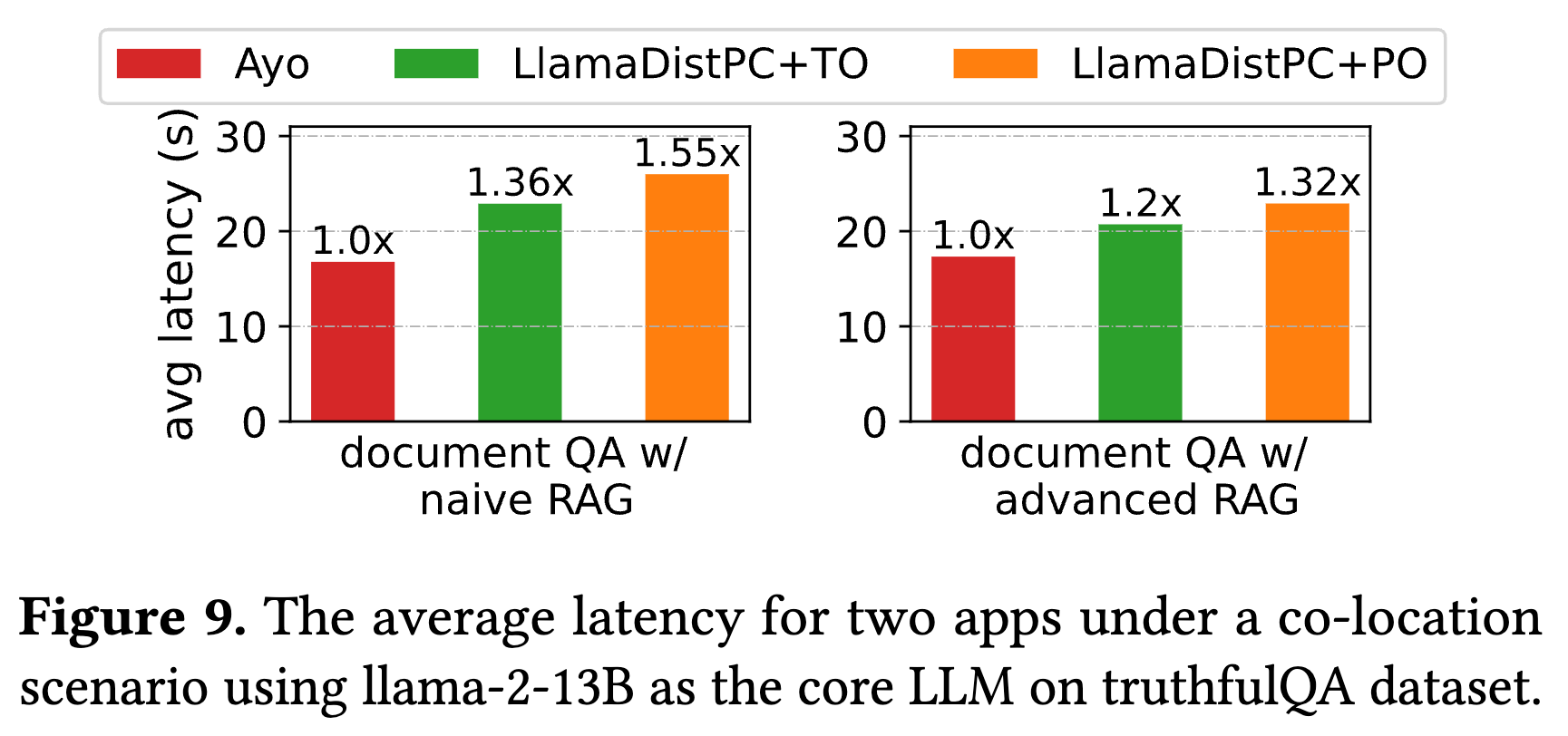
- 场景:同时运行“朴素 RAG”和“高级 RAG”两个应用,它们共享底层基础设施(LLM 和 向量库) 。
- 表现:Ayo 相比最强基线 LlamaDistPC 实现了 1.2 倍到 1.55 倍 的加速 。
- 结论:证明了 Ayo 的应用感知调度在多应用资源争抢场景下依然有效 。
7.4 消融实验
论文通过消融实验验证了 Ayo 各个核心组件的有效性。
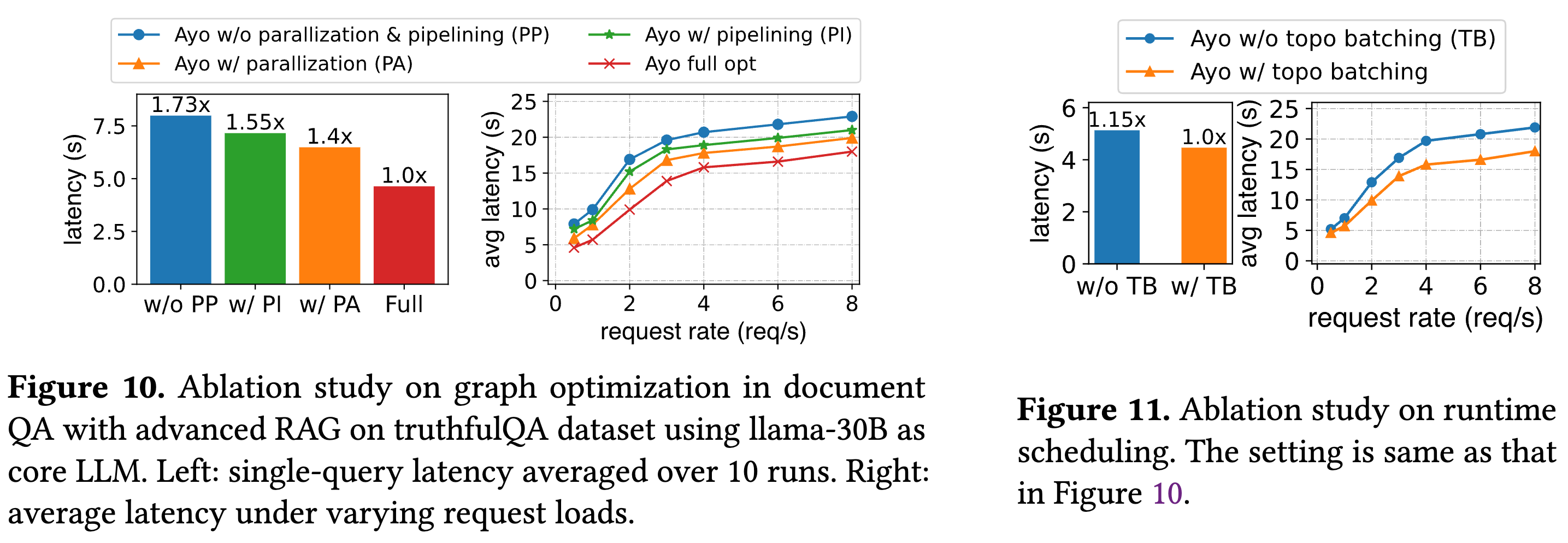
-
图优化 (Graph Optimization)
- 结果:
- 仅使用并行化 (PA) 或 仅使用流水线 (PI) 都能降低延迟。
- 全优化 (Full)(即同时启用并行化和流水线)效果最好,延迟最低 。
- 结果:
-
运行时调度 (Runtime Scheduling)
- 结果:开启 拓扑感知批处理 (Topology-aware batching, TB) 相比不开启(w/o TB),单次查询加速 1.15 倍,在多查询场景下平均延迟降低了 19.2% 。这证明了基于节点深度进行调度的有效性 。
7.5 开销分析
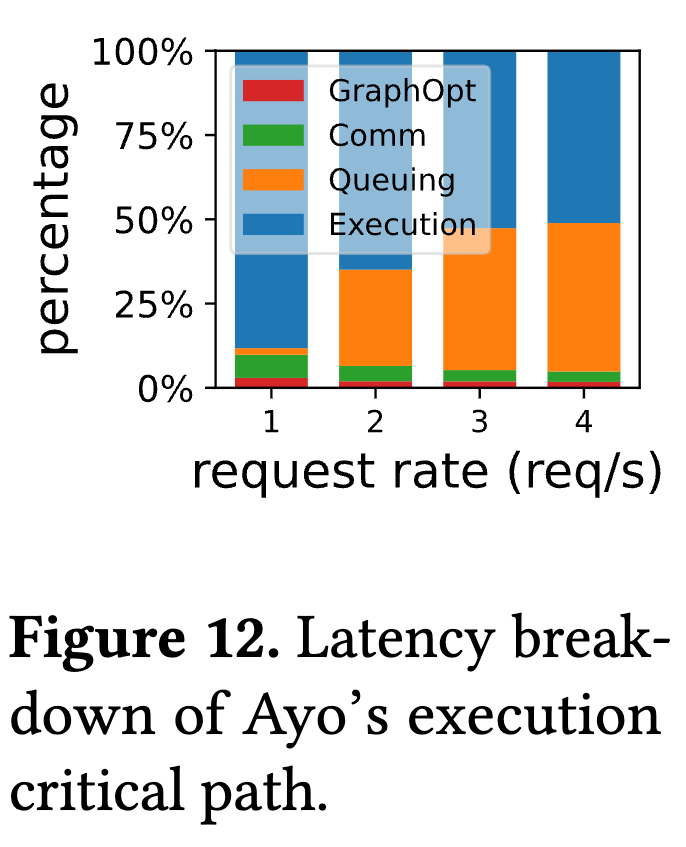
-
结果:
- 图优化开销 (GraphOpt):非常低,仅占总延迟的 1.3% 到 3% 。
- 通信开销 (Comm):仅占 3.1% 到 6.2% 。
-
结论:Ayo 引入的额外系统开销相对于其带来的性能提升是微乎其微的。
思考
Ayo 的分步和分层设计是不是也能融合成一步以实现端到端优化?
如何使得自主代理场景使用 Ayo 式优化?
Towards End-to-End Optimization of LLM-based Applications with Ayo