ShareGPT4Video: Improving Video Understanding and Generation with Better Captions
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | ShareGPT4Video: Improving Video Understanding and Generation with Better Captions |
| 作者 | Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, Li Yuan, Yu Qiao, Dahua Lin, Feng Zhao, Jiaqi Wang |
| 机构 | USTC, CUHK, PKU, Shanghai AI Lab |
| 来源 | 2024 arXiv: 2406.04325v1 |
| 总结 | 提出“差分滑动窗口”字幕生成策略,构建了包含大规模高质量密集字幕的数据集及高效字幕模型,显著提升了视频理解(LVLM)与生成(T2VM)任务的性能 |
摘要
本文提出了 ShareGPT4Video 系列工作,旨在通过密集且精确的字幕促进大视频语言模型(LVLMs)的视频理解能力和文本生成视频模型(T2VMs)的视频生成能力。该系列包含三个部分:
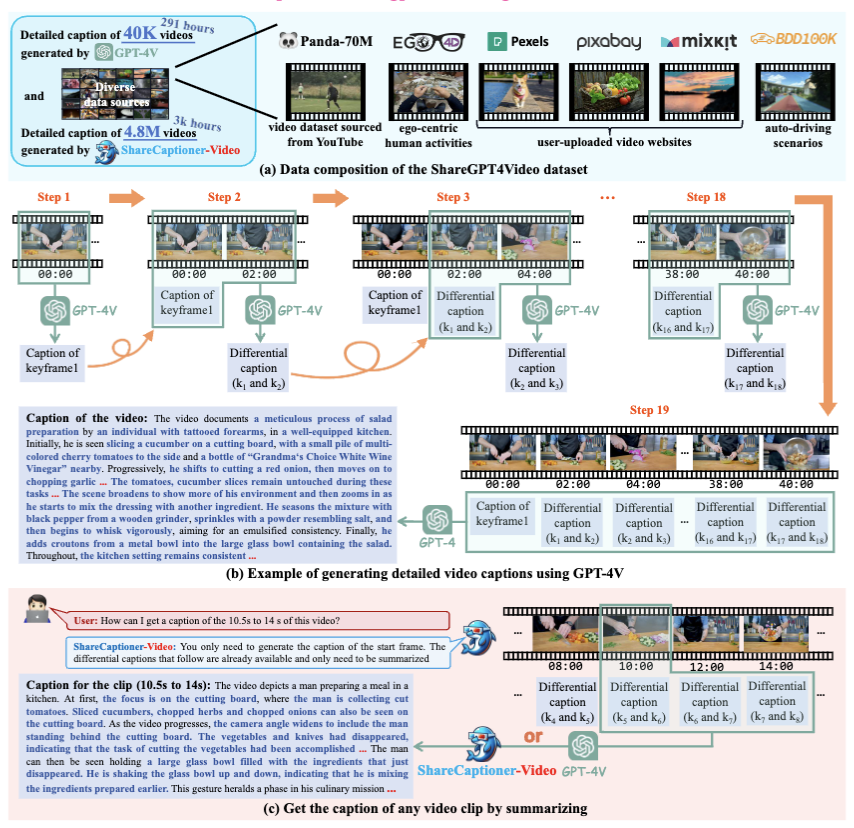
1. ShareGPT4Video 数据集:包含 40K 由 GPT-4V 标注的视频密集字幕,涵盖不同的视频时长和来源,通过精心设计的数据过滤和标注策略开发而成。
2. ShareCaptioner-Video 模型:一个适用于任意视频的高效且能力强大的字幕生成模型,并利用它标注了 480 万(4.8M)个高质量美学视频。
3. ShareGPT4Video-8B 模型:一个简单而出色的 LVLM,在三个先进的视频基准测试中达到了 SOTA 性能。
为实现这一目标,除去不可扩展且昂贵的人工标注外,我们发现直接使用 GPT-4V 通过简单的多帧或帧拼接输入策略生成的字幕细节较少,且有时会出现时间上的混淆。我们认为设计高质量视频字幕策略的挑战在于三个方面:
1. 帧间精确的时间变化理解。
2. 帧内详细的内容描述。
3. 针对任意长度视频的帧数可扩展性。
为此,我们精心设计了差分视频字幕策略(Differential Video Captioning Strategy),该策略在为任意分辨率、长宽比和时长的视频生成字幕时,具有稳定、可扩展且高效的特点。基于此策略,我们构建了 ShareGPT4Video,其中包含 40K 涵盖广泛类别的高质量视频,其生成的字幕包含丰富的世界知识、对象属性、摄像机运动,以及至关重要的、对事件的详细且精确的时间描述。基于 ShareGPT4Video,我们进一步开发了 ShareCaptioner-Video,这是一个卓越的字幕生成器,能够高效地为任意视频生成高质量字幕。我们利用它标注了 480 万个美学视频,并在 10 秒文本生成视频任务上验证了其有效性。在视频理解方面,我们在几种当前的 LVLM 架构上验证了 ShareGPT4Video 的有效性,并提出了我们卓越的新模型 ShareGPT4Video-8B。所有的模型、策略和标注都将开源,我们希望该项目能成为推动 LVLMs 和 T2VMs 社区发展的关键资源。
内容
1 背景 & 动机
1.1 现有痛点
尽管大语言模型驱动了多模态学习(Image-Text)的快速发展,但在视频领域(Video Understanding & Generation),高质量的数据集仍然匮乏:
- 现有数据缺陷: 视频往往只配有简短的字幕(Brief Captions),缺乏对视频内容的详细描述,尤其是时序上的变化。
- 双向瓶颈:
- 对于 LVLMs(视频理解): 简短的文本限制了模型对视频细节的理解能力。
- 对于 T2VMs(视频生成): 缺乏细节的文本导致生成的视频无法精确控制内容和运镜,尤其是在复杂指令下。
1.2 核心挑战
作者指出,设计一个高质量的视频 Caption 策略面临三大挑战:
- 帧间精确的时序理解(Inter-frame precise temporal change understanding): 视频与图像最大的区别在于时间维度。模糊的时间描述会导致模型训练时的混淆。
- 帧内详细的内容描述(Intra-frame detailed content description): 需要像 Image Caption 一样丰富。
- 任意长度的可扩展性(Frame-number scalability): 视频长度差异巨大(从几秒到几分钟),策略必须具有鲁棒性。
1.3 现有方法的局限性
作者尝试了直接利用 GPT-4V 进行标注的简单策略,但发现均不可行:
- 多帧直接输入(Multiple Frames Input): 如果直接将多帧带时间戳输入 GPT-4V,模型表现不稳定,经常出现时序幻觉(Temporal Hallucination),即无法正确理解帧与帧之间的先后逻辑关系。
- 拼接输入(Concatenation): 将多帧拼成一张大图。随着帧数增加,分辨率被压缩,导致细节丢失(如 Figure 12 所示)。
- 现有 LVLM/T2VM 现状: 绝大多数现有工作(如 Video-LLaVA, Sora 等)受限于数据质量,未能充分发挥模型潜力。
2. ShareGPT4Video 数据集构建(Dataset Construction)
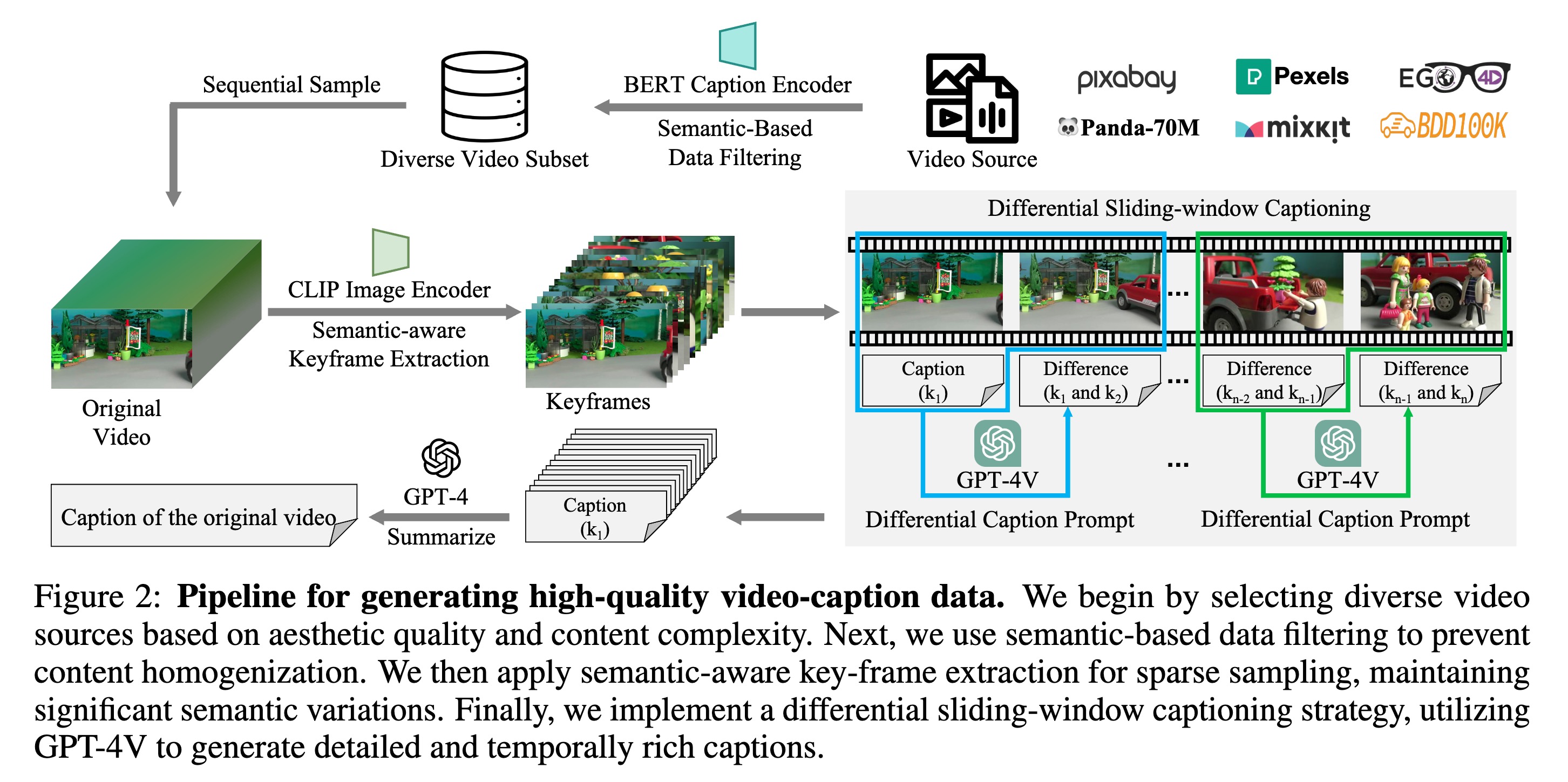
为了解决上述问题,作者提出了 ShareGPT4Video 数据集构建流程,包含 40K GPT-4V 高质量标注视频。核心在于设计了一套从筛选到生成的完整 Pipeline。
整个流程分为四步:源数据采样 -> 语义过滤 -> 语义关键帧提取 -> 差分滑动窗口 Caption 生成。
2.1 数据源与语义过滤(Data Collection & Filtering)
- 多样化数据源:
- Panda-70M: 涵盖广泛的真实世界场景(复杂内容与转场)。
- Pexels / Pixabay / User-uploaded: 高美学质量视频,用于提升 T2VM 的生成美感。
- Ego4D / BDD100K: 补充第一人称视角和自动驾驶场景。
- 语义去重策略(Semantic-Based Data Filtering):
- 动机:避免内容同质化。
- 算法逻辑(基于附录 A.6):
- 使用轻量级模型(Panda-Student)为视频生成一句简短 Caption。
- 使用 BERT-Base-Uncased 提取 Caption 的 CLS token 作为语义特征向量。
- 计算新视频与候选池中现有视频的余弦相似度。
- 只有当最大相似度 低于阈值 时,才将该视频加入数据集。
2.2 语义感知关键帧提取(Semantic-aware Key-frame Extraction)
为了解决视频在时间维度上的冗余,同时保留语义完整性,作者设计了一种动态采样策略:
- 算法逻辑(基于附录 A.6):
- 设定固定的采样间隔(如 2秒)获取初始帧序列 $V$。
- 使用 CLIP-Large Image Encoder 提取每一帧的全局语义特征。
- 动态保留: 计算当前帧与上一个已选关键帧的语义相似度 $d$。
- 如果 $d < Threshold$(说明内容发生了显著变化),则保留该帧为关键帧。
- 否则,丢弃该帧(认为是冗余)。
- 保底机制: 视频的最后一帧总是被保留,以确保完整性。
2.3 差分滑动窗口字幕策略(DiffSW: Differential Sliding-Window Captioning)
这是本文最核心的贡献,用于解决长视频的时序理解和 Token 限制问题。
- 核心思想: 将“多帧描述”任务转化为“差分描述”任务。
- 工作流:
- 滑动窗口(Size=2): 每次只输入当前帧($I_t$)和上一帧($I_{t-1}$)。
- 上下文增强: 将上一帧的差分 Caption($\Delta C_{t-1}$)也作为输入提供给 GPT-4V。
- Benefit: 提供了隐式的历史信息,减少幻觉。
- GPT-4V 任务: 生成当前帧相对于上一帧的变化描述(Differential Caption)。
- 首帧处理: 第一帧没有前序帧,直接生成标准详细描述。
- 优势:
- 稳定性: 固定输入两帧,GPT-4V 不会被过多的上下文干扰。
- 可扩展性: 无论视频多长,都可以通过滑动窗口处理。
2.4 分层 Prompt 设计(Hierarchical Prompt Design)
为了让 GPT-4V 和 GPT-4 精确执行任务,作者设计了一套结构化的 Prompt 体系(详见附录 A.2 & A.3)。
Prompt 结构包含四个组件:
- Character: 定义角色(如“优秀的视频帧分析师”)。
- Skills: 列出具体能力要求。
- Constraints: 明确禁止的行为(如“不要使用隐喻”、“不要提及帧ID”)。
- Structured Input: 规范输入格式。
2.4.1 差分 Caption Prompt(针对 GPT-4V)
- 目标: 捕捉帧间的细微变化。
- 关键 Skills 定义:
- Skill 1(Action): 描述物体动作或行为的变化。
- Skill 2(Environment): 描述背景/环境的变化。
- Skill 3(Appearance): 描述物体状态/属性的变化。
- Skill 4(Camera): 重点识别运镜(Panning, Zooming 等),这对视频生成至关重要。
2.4.2 总结 Prompt(针对 GPT-4)
- 目标: 将一系列碎片化的差分 Caption 融合成一段流畅、连贯的视频描述。
- 输入: 包含时间戳的所有差分 Caption 列表。
- 约束: 要求保持时间线的完整性,去除不确定的信息,输出客观陈述。

这是一个生成结果示例。可以看到 DiffSW 生成的文本非常长且包含精确的时序词(“Initially”, “Progressively”, “Following the chopping”),并准确捕捉了如“搅拌”、“加入配料”等细微动作。
3 ShareCaptioner-Video 模型
基于构建的高质量数据集,作者训练了 ShareCaptioner-Video。该模型基于 InternLM-XComposer2-4KHD 架构微调,被设计为一个“四合一”的通用视频 Caption 模型,能够根据不同场景灵活切换模式。
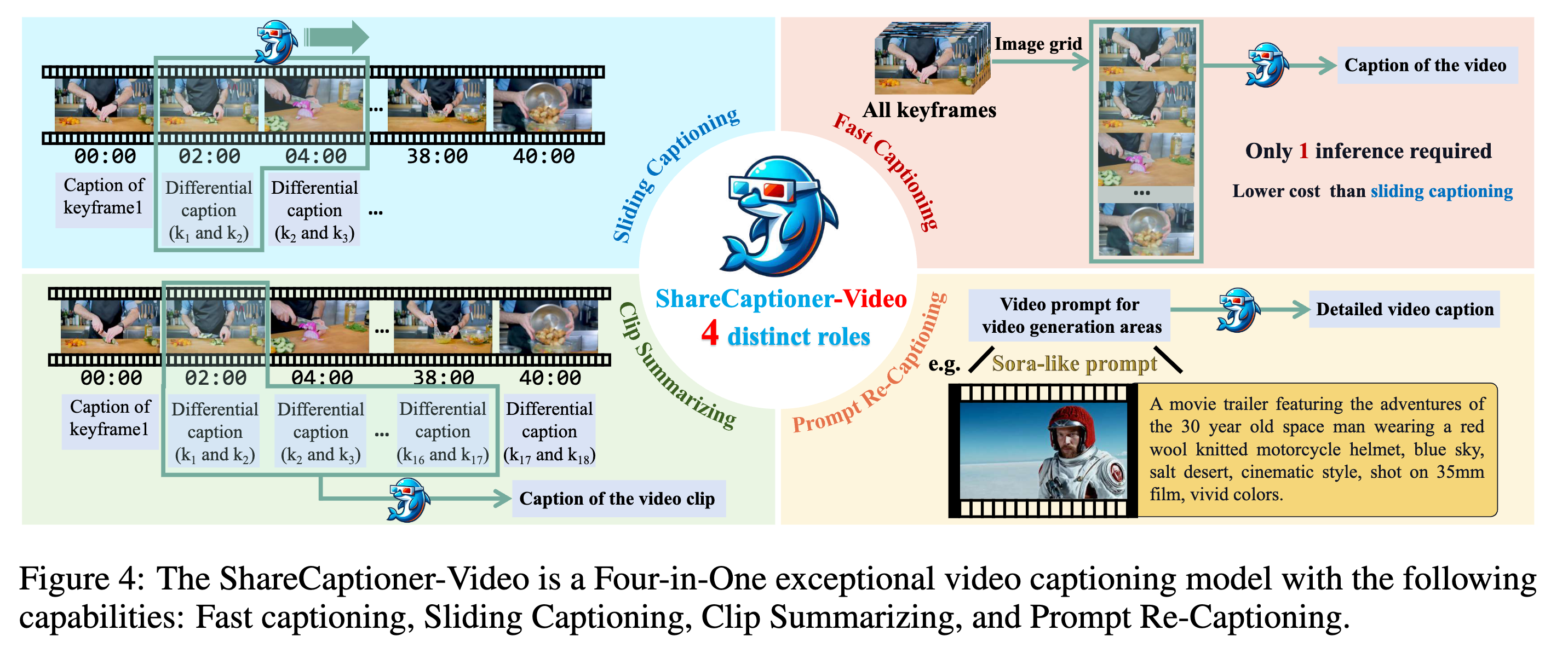
四种核心能力
- 快速 Caption(Fast Captioning):
- 机制:将视频的所有关键帧拼接成一个垂直延长的 Image Grid 作为输入。
- 适用场景:短视频。
- 优势:推理速度快,只需一次前向传递。
- 滑动窗口 Caption(Sliding Captioning):
- 机制:支持流式处理,采用与数据集构建时相同的 DiffSW(差分滑动窗口) 策略。输入为
(Frame_t, Frame_{t-1}, Diff_Caption_{t-1})。 - 适用场景:长视频。
- 优势:生成质量最高,包含详尽的时序细节。
- 机制:支持流式处理,采用与数据集构建时相同的 DiffSW(差分滑动窗口) 策略。输入为
- 片段摘要(Clip Summarizing):
- 机制:输入为一系列已经生成的“差分描述(Differential Descriptions)”,输出为该片段的完整 Caption。
- 优势:无需重新处理视频帧,直接对文本进行摘要,效率极高。
- Prompt 重写/重标注(Prompt Re-Captioning):
- 背景:T2VM(文生视频模型)通常使用 Dense Caption 训练,但用户输入的 Prompt 往往很短(如 Sora-style prompt)。这导致推理时存在 分布偏移(Format Misalignment)。
- 机制:作者构造了
(Sora-style prompt, Dense Caption)数据对,并训练模型将用户的简短 Prompt 重写为模型偏好的 Dense Caption 格式。 - 优势:确保 T2VM 在推理时也能接收到高质量、详细的 Prompt,提升生成控制力。
4. 实验(Experiments)
4.1 实验环境与设置(Experimental Setup)
- ShareGPT4Video-8B 训练:
- 基座模型: LLaVA-Next-8B。
- 视觉编码: 均匀采样 16 帧,排列成 4x4 Image Grid(遵循 IG-VLM 策略)。
- 训练资源: 8张 A100 GPU,仅需约 5 小时(全量微调 Vision Encoder 和 MLP,LLM 使用 LoRA)。
- T2VM(视频生成)训练:
- 模型: Latte-XL(基于 DiT),文本编码器为 T5-XXL。
- 训练规模: 第一阶段 50k 步(Image+Video 混合训练),第二阶段仅 Video 训练。需要约 36K Ascend GPU Hours。
4.2 视频理解性能(Video Understanding)
作者首先验证了数据集对现有 LVLM 的增益,随后展示了自研模型 ShareGPT4Video-8B 的性能。
-
通用增益(Universal Gain):
- 将 VideoLLaVA 和 LLaMA-VID 训练数据中的一小部分(28K)替换为 ShareGPT4Video 数据。
- 结果: 在 VideoBench, MVBench, TempCompass 上均有一致提升。
-
SOTA 表现(ShareGPT4Video-8B):
- TempCompass(时序理解): 取得了 61.5% 的准确率,比之前的最佳模型(VideoLLaVA-7B)高出 11.6%。这直接证明了密集时序 Caption 对模型理解时间维度的巨大帮助。
- 综合 Benchmark: 在 VideoBench 和 MVBench 上分别超越 SOTA 2.7% 和 8.2%。
4.3 视频 Caption 质量分析(Video Captioning Quality)
为了证明 ShareCaptioner-Video 的标注能力可以替代 GPT-4V,作者进行了定性和定量分析。
- 词汇构成分析(Lexical Composition):
- ShareCaptioner 生成的 Caption 在名词、动词、形容词的分布比例上与 GPT-4V 高度一致,证明其信息密度相当。
- 人工评测(Human Preference):
- 在“遗漏与捏造”、“失真”、“时序错配”三个维度的盲测中,ShareCaptioner 与 GPT-4V 互有胜负,整体表现 On Par(持平)。
4.4 视频生成性能(Video Generation)
使用 ShareCaptioner-Video 标注的 4.8M 视频训练 Latte-XL 模型。

- 定性对比:
- Short Caption 训练的模型: 难以遵循复杂的 Prompt(如“烟花从红变黄”),容易忽略颜色和形状的变化。
- Detailed Caption 训练的模型: 精确控制了语义内容和摄像机运动(Camera Control),生成的视频画面更丰富、动态感更强。
思考
"差分"是视频理解的本质: DiffSW(差分滑动窗口) 策略让我想起了残差网络的内容,视频与图像的本质区别在于 Change(变化)。传统的 Video Caption 往往是对每一帧做 Image Caption 然后拼接,或者直接让模型“看”所有帧,这导致模型很容易忽略微小的动作变化。作者强制 GPT-4V 关注 Current Frame 与 Previous Frame 的差异,从根本上抓住了视频的时序特征。能不能借助残差的思想构建视频的架构,以解决ViT中分离自注意力的妥协?
ShareGPT4Video: Improving Video Understanding and Generation with Better Captions