Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks |
| 作者 | Yunfan Gao, Yun Xiong, Meng Wang, Haofen Wang |
| 来源 | 2024 arXiv:2407.21059v |
| 总结 | 提出模块化 RAG 框架,将 RAG 系统拆解为独立的模块和算子,并总结了线性、条件、分支和循环等 RAG 流模式 |
摘要
检索增强生成 显著提升了大型语言模型处理知识密集型任务的能力。随着应用场景需求的增加,RAG 系统整合了更高级的检索器、LLM 及其他辅助技术,导致系统复杂性急剧上升。然而,快速的技术进步使得传统的“检索-生成”范式难以统一现有的各种方法。 在此背景下,本文指出了现有 RAG 范式的局限性,并引入了 Modular RAG(模块化 RAG) 框架。通过将复杂的 RAG 系统分解为独立的 Modules(模块) 和专门的 Operators(算子),该框架实现了高度的可重构性。Modular RAG 超越了传统的线性架构,融合了 Routing(路由)、Scheduling(调度) 和 Fusion(融合) 等高级机制。基于广泛的研究,本文进一步识别了 Linear(线性)、Conditional(条件)、Branching(分支) 和 Looping(循环) 四种普遍的 RAG 模式,并对其实现细节进行了全面分析。最后,文章探讨了新算子和范式的潜在发展,为 RAG 技术的持续演进和实际部署奠定了坚实的理论和实践基础。
内容
1 引言 & 动机
1.1 RAG 范式的演进路径
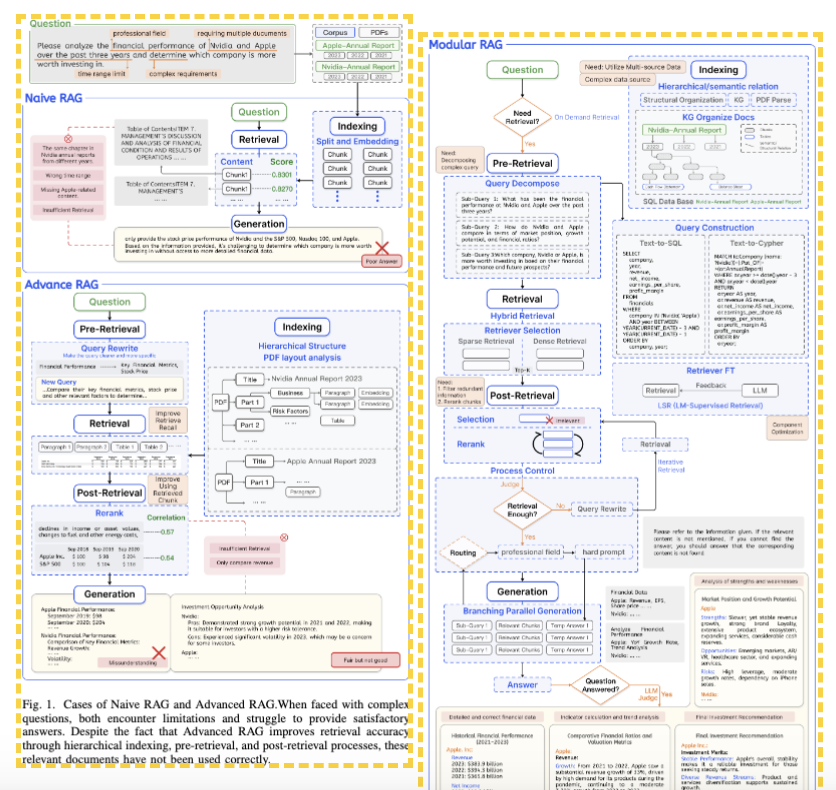
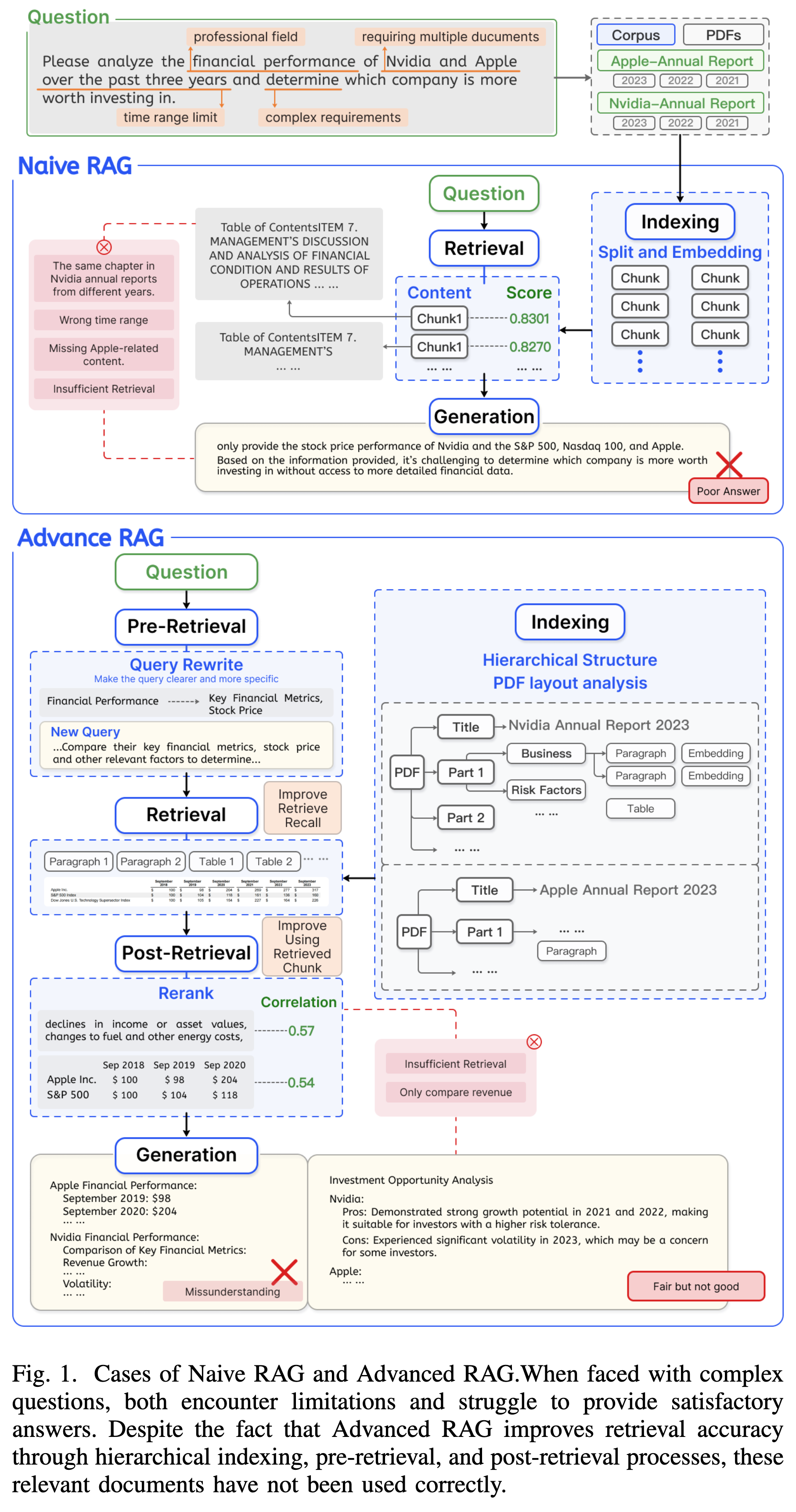
论文将 RAG 的发展历程归纳为三个阶段,每一阶段的演进都是为了解决前一阶段面临的特定痛点。
-
Naive RAG
- 定义:最早期的“索引-检索-生成”(Index-Retrieve-Generate)线性流程。
- 机制:直接根据 Query 检索相关片段(Chunks)并喂给 LLM。
- 局限性:
- 浅层理解:仅依赖简单的语义相似度,难以处理复杂 Query。
- 检索冗余与噪声:检索到的内容可能包含大量无关信息,导致 LLM 产生幻觉或回答错误。
-
Advanced RAG
- 定义:在 Naive RAG 基础上增加了 Pre-Retrieval(检索前) 和 Post-Retrieval(检索后) 的处理步骤。
- 机制:
- Pre-Retrieval:进行 Query Rewrite(查询重写)等操作以提升检索精度。
- Post-Retrieval:进行 Rerank(重排序)以筛选高质量上下文。
- 局限性:虽然优化了性能,但本质上仍受限于线性流程,缺乏灵活性,难以应对复杂的真实世界应用需求。
-
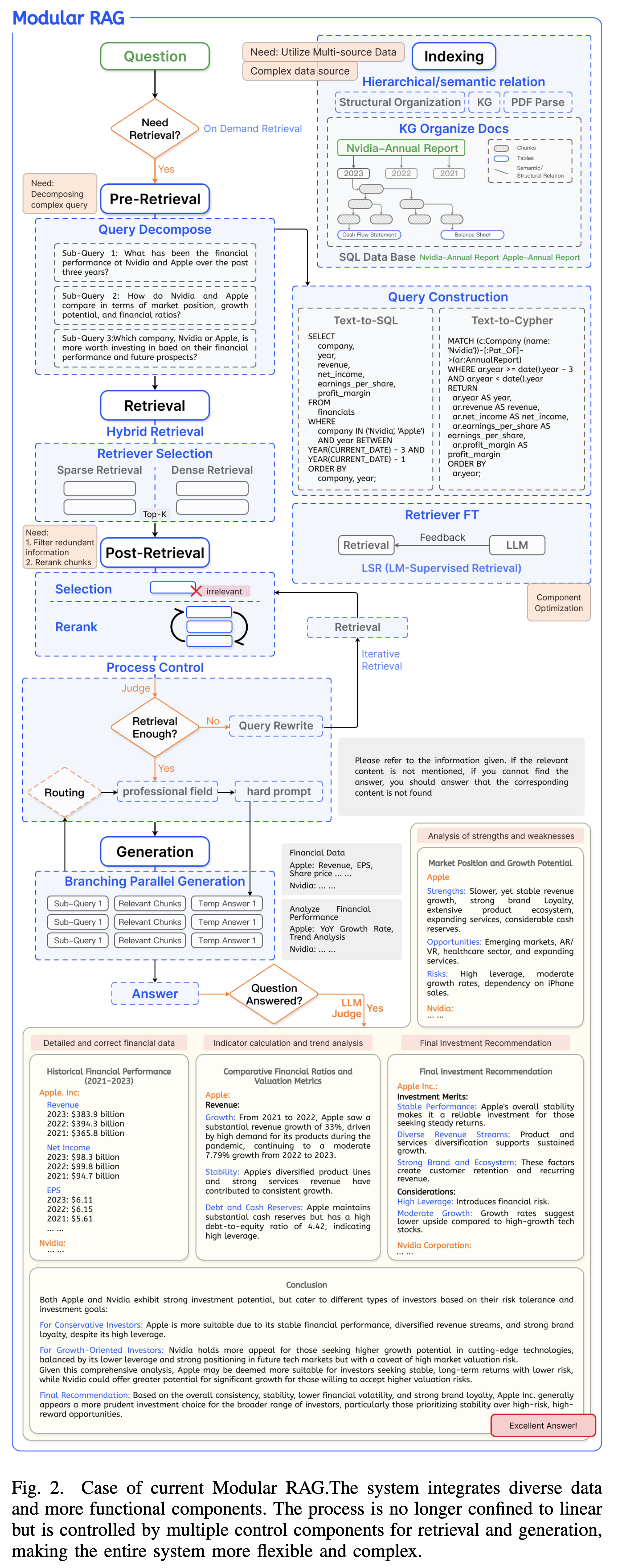
Modular RAG
- 定义:打破线性流程,将系统拆解为独立的模块(Modules)和算子(Operators),支持非线性的编排(如循环、分支)。
- 核心理念:LEGO-like(乐高式) 的可重构框架。
1.2 模块化的核心动机
尽管 Advanced RAG 提升了检索质量,但面对日益复杂的应用场景,现有的固定范式已捉襟见肘。论文提出了推动 RAG 向模块化演进的四大挑战:
-
复杂数据源的集成(Complex Data Sources)
- RAG 不再局限于非结构化文本,通过 Query Construction(如 Text-to-SQL)开始整合表格、Knowledge Graph(知识图谱) 等异构数据。线性流程难以兼容这种多样性。
-
工作流编排与调度(Workflow Orchestration)
- 系统不再是单一的“查完就写”。现代 RAG 需要:
- Iterative(迭代):多轮检索。
- Adaptive(自适应):由 LLM 自主判断是否需要检索。
- Branching(分支):并行处理不同子任务。
- 这要求系统具备高级的 Routing(路由) 和 Scheduling(调度) 能力。
- 系统不再是单一的“查完就写”。现代 RAG 需要:
-
系统可维护性与透明度(Maintainability)
- 随着组件增多,调试变得困难。模块化设计允许开发者像搭积木一样独立优化特定算子,快速定位问题。
-
组件选择与优化(Component Optimization)
- 不同的任务需要不同的 Retriever 或 LLM 组合。模块化框架允许根据特定场景灵活替换和微调组件(如 Retriever FT, Generator FT)。
总结:Modular RAG 的提出,旨在从架构层面解决 RAG 系统日益增长的复杂性问题,将 RAG 从一个简单的 pipeline 升级为一个支持条件判断、循环和分支的图结构(Graph)系统。

2 模块化框架定义(The Modular Framework)
为了应对日益增长的系统复杂性,论文正式提出了 Modular RAG 的层级化定义,将 RAG 系统抽象为一个由不同粒度组件构成的计算图。
2.1 三层级架构(Three-Level Hierarchy)
Modular RAG 采用自顶向下的三层结构来组织系统:
- L1: Module(模块)
- 定义:RAG 系统的核心流程阶段。
- 示例:
Retrieval(检索),Generation(生成),Orchestration(编排)。
- L2: Sub-module(子模块)
- 定义:模块内的具体功能单元。
- 示例:在
Pre-retrieval模块下的Query Rewrite(查询重写)或Query Expansion(查询扩展)。
- L3: Operator(算子)
- 定义:子模块的具体实现算法或模型。
- 示例:
Query Rewrite可以由LLM Rewrite算子或HyDE算子实现。
2.2 RAG Flow(RAG 流)
基于上述定义,一个 RAG 系统可以被表示为一个有向图或序列,称为 RAG Flow。
- 系统表示:$G = {q, D, \mathcal{M}, {\mathcal{M}_s}, {Op}}$
- 关系:
- Naive RAG 是最简单的线性链:Retrieve -> Read。
- Advanced RAG 是增加了 Pre/Post-retrieval 模块的特例。
- Modular RAG 则是通用的图结构,支持非线性连接。
3 框架核心 I:模块与算子
作者总结了当前 RAG 技术栈中的六大核心模块。与传统 RAG 相比,Orchestration(编排) 模块的引入是 Modular RAG 的最大特色。
3.1 Indexing(索引模块)
旨在建立高效的数据组织形式,以应对不完整的上下文表达和检索噪声。
- Chunk Optimization(切片优化)
- Small-to-Big: 索引小切片(提高检索精准度),但在生成时返回其所属的父文档(提供完整上下文)。
- Sliding Window: 使用重叠窗口增强语义连贯性。
- Structure Organization(结构化组织)
- Knowledge Graph(KG)Index: 利用知识图谱建立概念间的实体连接,将检索转化为图遍历,提高多跳推理能力。
- Hierarchical Index: 保留 PDF/文档的章节层级结构。
3.2 Pre-retrieval(检索前模块)
解决用户原始 Query 表达不清或与文档语义空间不匹配的问题。
- Query Expansion(查询扩展)
- Multi-Query: 利用 LLM 生成多个视角的查询。
- Sub-Query: 针对复杂问题,使用 Least-to-Most 策略将其分解为多个子问题并行或串行检索。
- Query Transformation(查询变换)
- Rewrite: 使用专门的小模型或 LLM 重写查询(如解决指代消解)。
- HyDE(Hypothetical Document Embeddings): 生成一个“假设性答案”,并基于该答案的向量进行检索(以通过“答案-答案”相似度替代“问题-文档”相似度)。
- Query Construction(查询构造)
- 针对结构化数据源,使用 Text-to-SQL 或 Text-to-Cypher 转换自然语言。
3.3 Retrieval(检索模块)
核心是选择合适的检索器并在必要时进行领域适配。
- Retriever Selection(检索器选择)
- Hybrid Retrieval: 结合 Sparse Retriever(BM25, 关键词匹配)和 Dense Retriever(Embedding, 语义匹配)的优势,通常能获得最佳的鲁棒性。
- Retriever Fine-tuning(检索器微调)
- SFT(Supervised Fine-Tuning): 使用对比学习(Contrastive Learning)拉近正样本、推远负样本。
- LSR(LM-supervised Retriever): 利用 LLM 的输出作为监督信号来微调检索器,使检索结果更符合 LLM 的偏好。
3.4 Post-retrieval(检索后模块)
解决“Lost in the Middle”现象和上下文窗口限制。
- Rerank(重排序)
- Model-based: 使用 Cross-Encoder 对检索回来的 Top-K 文档进行精细打分重排,是提升 RAG 效果最显著的手段之一。
- Compression & Selection(压缩与选择)
- LLMLingua: 基于信息熵(Perplexity)压缩提示词,移除冗余 Token,保留关键信息。
- LLM-Critique: 让 LLM 自我评估检索内容的效用,过滤掉无关或有害的片段。
3.5 Generation(生成模块)
- Generator Fine-tuning: 使用领域数据对 LLM 进行指令微调(Instruct-Tuning)。
- Verification(验证)
- Knowledge-base Verification: 生成后检索外部知识库(如 Wikipedia)验证事实准确性。
- Self-Correction: 如果发现幻觉或矛盾,循环触发再生。
3.6 Orchestration(编排模块)(核心)
这是控制 RAG Flow 的“大脑”,决定了系统如何动态执行。
- Routing(路由)
- 机制:根据 Query 的意图(Intent)或元数据(Metadata),将请求分发到不同的 RAG 流水线(例如:简单问题走 Naive RAG,复杂问题走多跳 RAG)。
- 实现:可以是基于规则的关键词匹配,也可以是基于语义的分类器。
- Scheduling(调度)
- 机制:决定“何时检索”以及“何时停止”。
- Active Retrieval: 如 FLARE 或 Self-RAG,模型在生成过程中主动判断置信度,低置信度时触发检索。
- Fusion(融合)
- 机制:在多分支(Branching)模式下,合并多个检索源或多个生成答案。
- RRF(Reciprocal Rank Fusion): 加权融合多个检索列表。
- Weighted Ensemble: 对多个生成的 Token 概率进行加权平均。
4 框架核心 II:RAG 流模式
作者对现有 RAG 研究进行了详尽的分类,识别出五种通用的设计模式。这些模式描述了模块(Modules)和算子(Operators)如何协同工作。
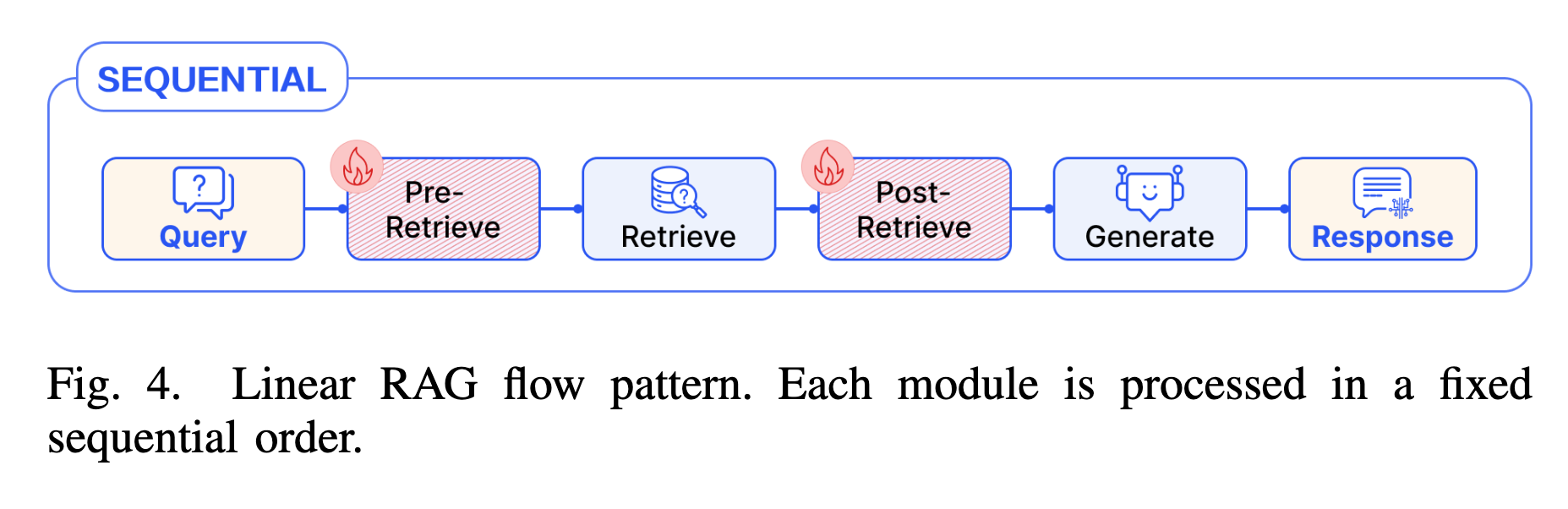
4.1 Linear Pattern (线性模式)
- 机制:模块按固定的顺序依次执行,是标准 RAG 的基础形式。
- 典型流程:Pre-retrieval $\to$ Retrieval $\to$ Post-retrieval $\to$ Generation。
- 案例:
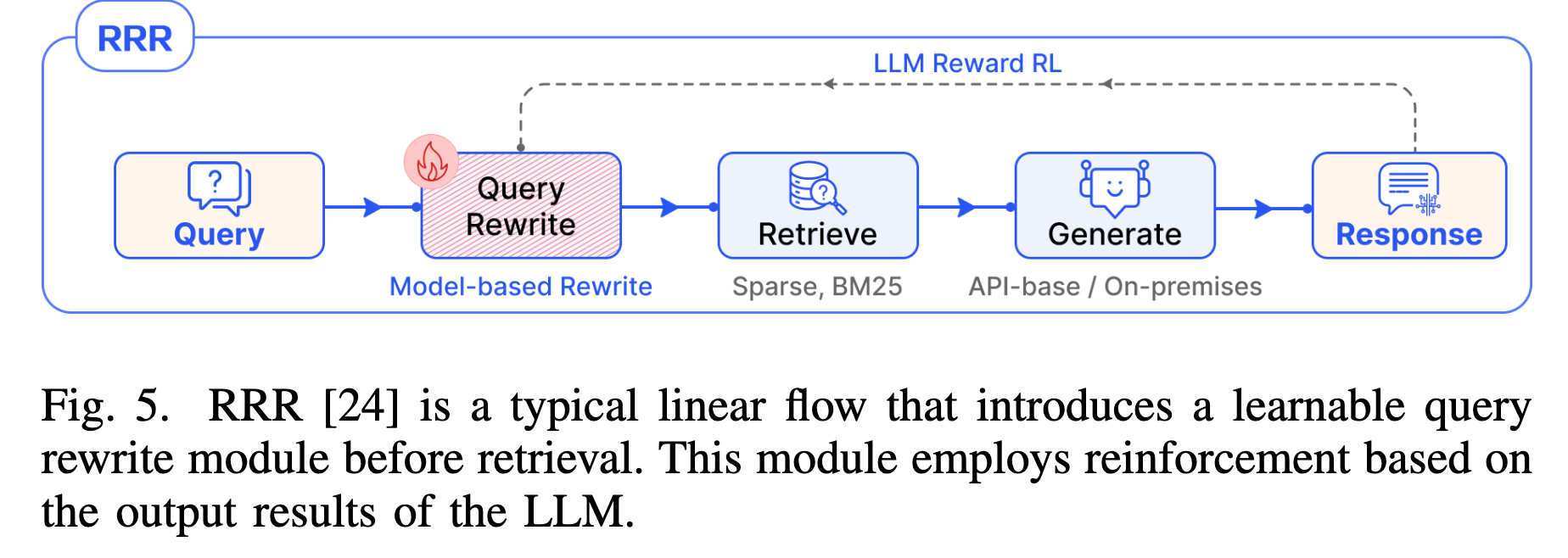
- RRR (Rewrite-Retrieve-Read): 在检索前引入一个可训练的 Query Rewrite 模块,利用强化学习优化重写策略,后续接标准的 BM25 检索和生成。
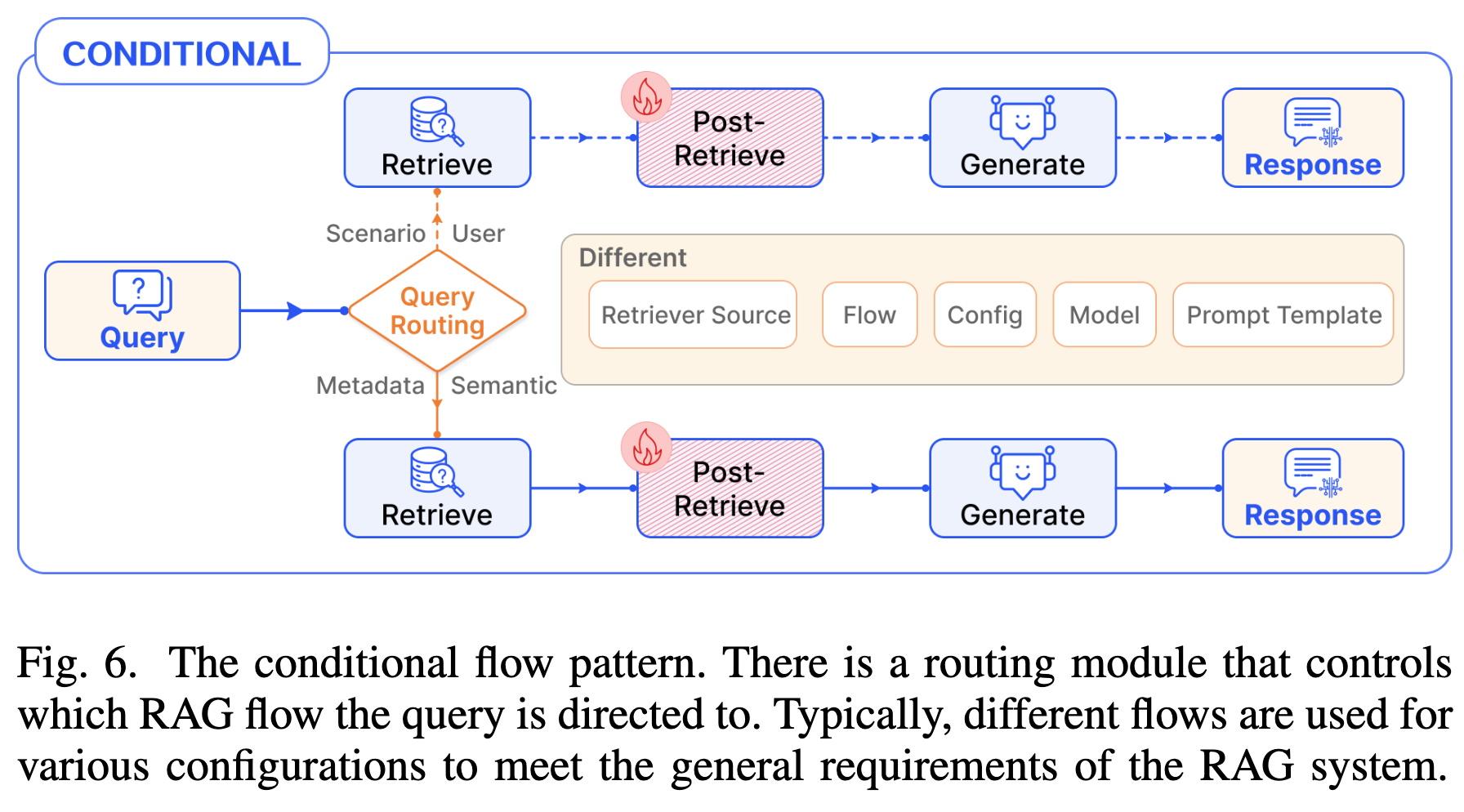
4.2 Conditional Pattern (条件模式)
- 机制:引入 Routing (路由) 模块,根据 Query 的类型或语义选择不同的执行路径。
- 场景:
- 针对不同领域的问题(如法律 vs. 医疗)路由到不同的知识库。
- 针对问题难度(简单 vs. 复杂)选择是否跳过检索(直接生成)或进行多跳检索。
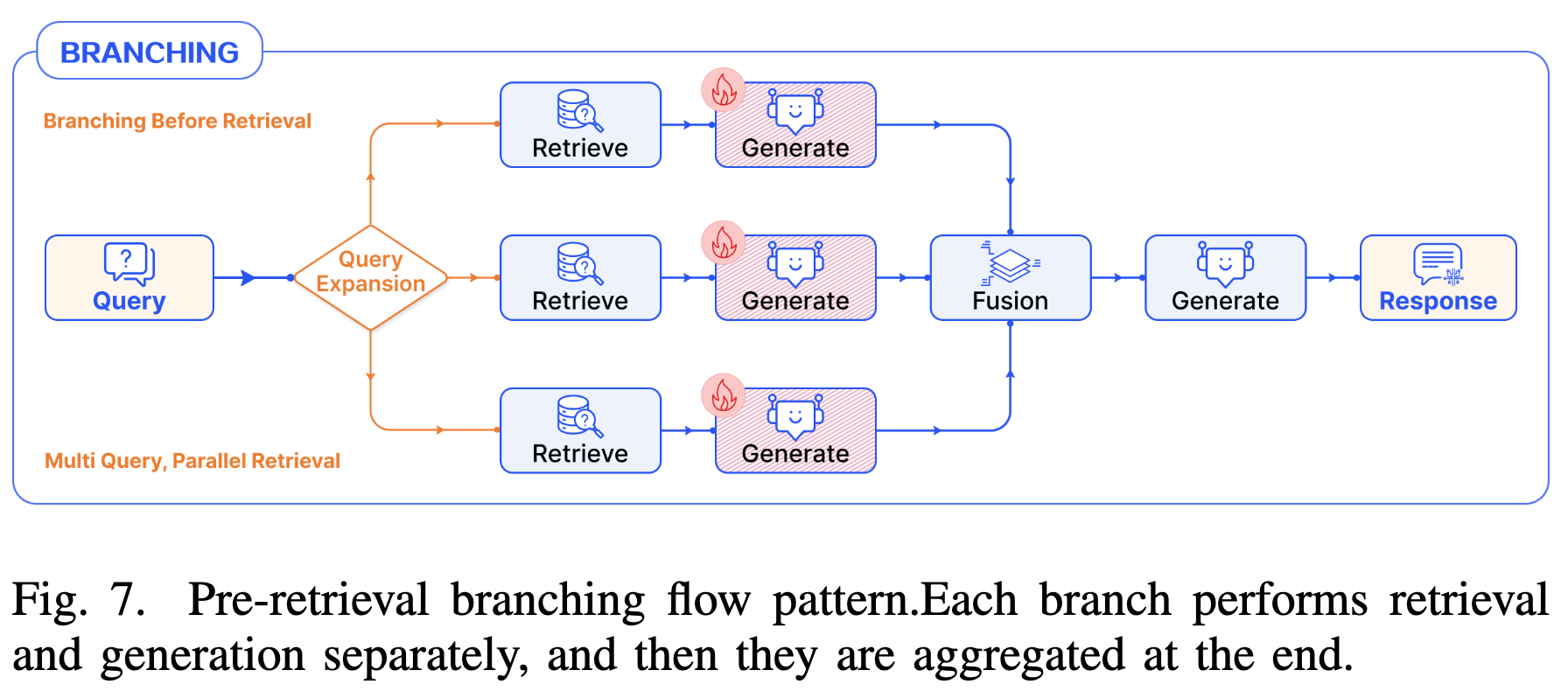
4.3 Branching Pattern (分支模式)
系统并行执行多个分支,最后通过 Fusion (融合) 模块整合结果。
- Pre-Retrieval Branching (检索前分支)
- 机制:即 Multi-Query。将原始 Query 扩展为多个子查询,并行检索,汇总所有相关文档后再统一生成。
- 优势:提高检索召回率,解决单一查询表达不全的问题。
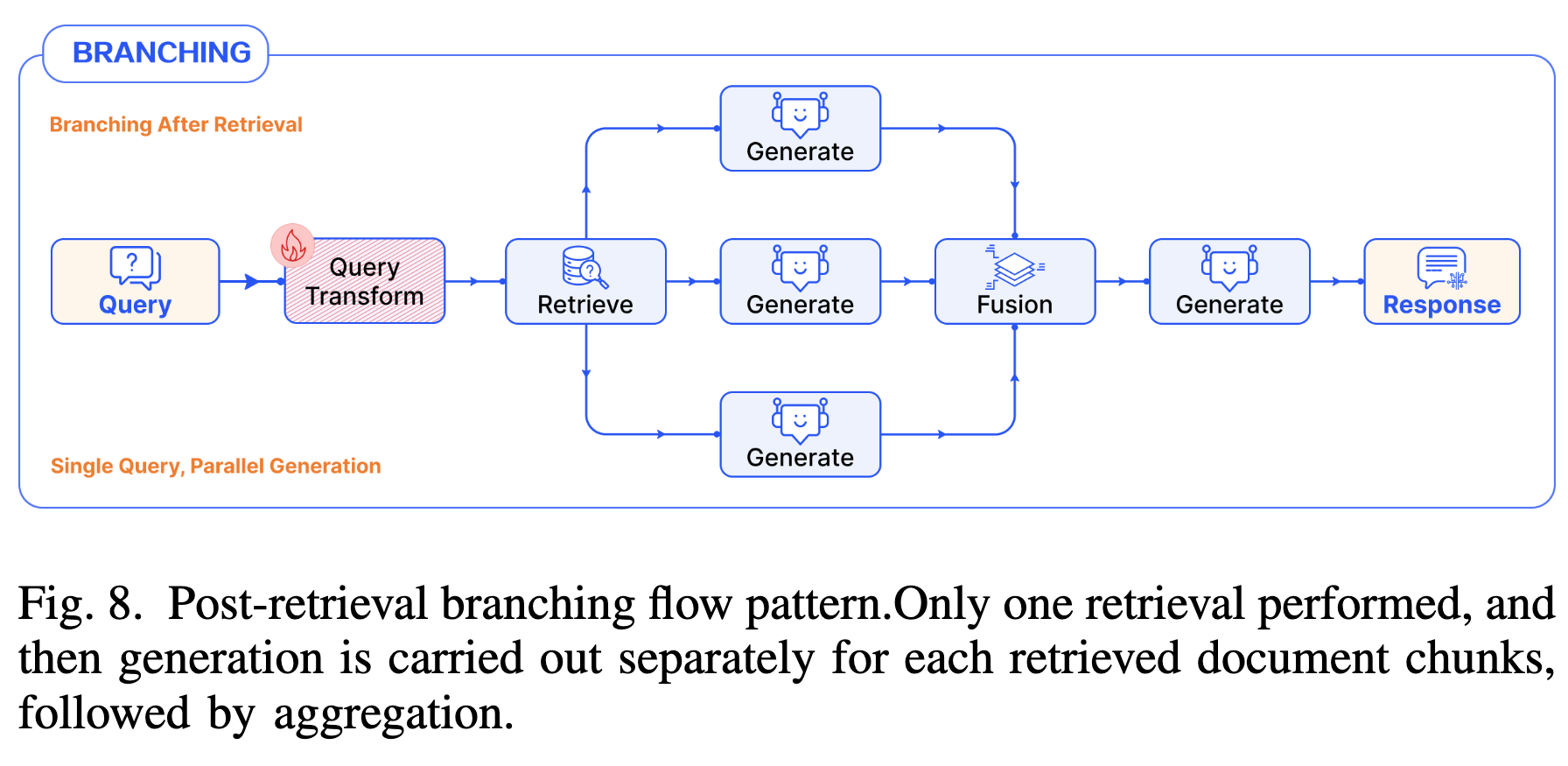
- Post-Retrieval Branching (检索后分支)
- 机制:单一 Query 检索回多个文档后,并行让 LLM 对每个文档单独生成答案(或中间结果),最后聚合。
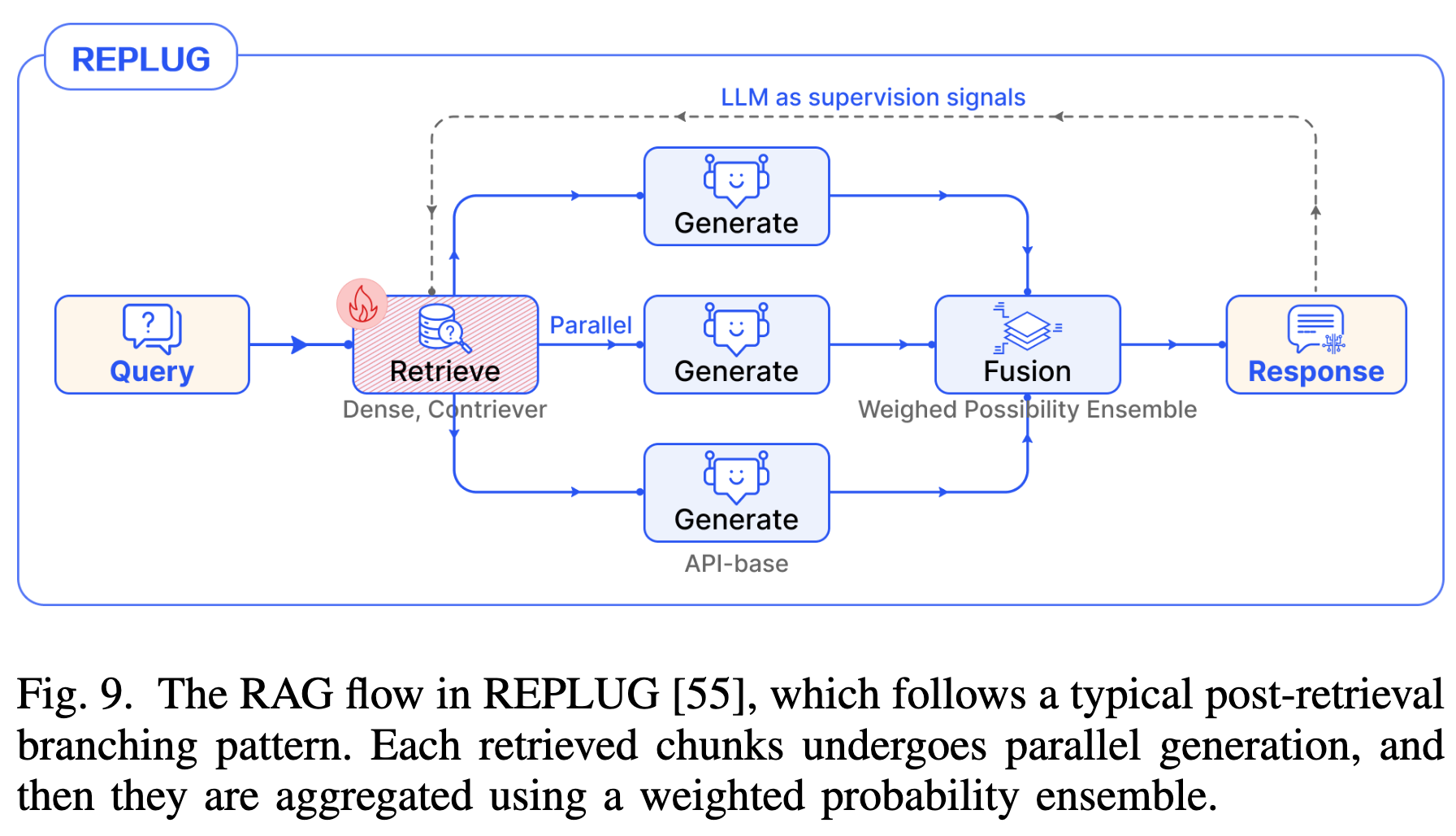
- 案例:REPLUG 对每个检索到的文档计算生成概率,通过加权集成(Weighted Ensemble)得出最终答案,并利用该信号监督检索器的更新。
4.4 Loop Pattern (循环模式)(Modular RAG 的精髓)

模块之间形成环路,支持多轮交互。这是处理复杂推理任务的关键。
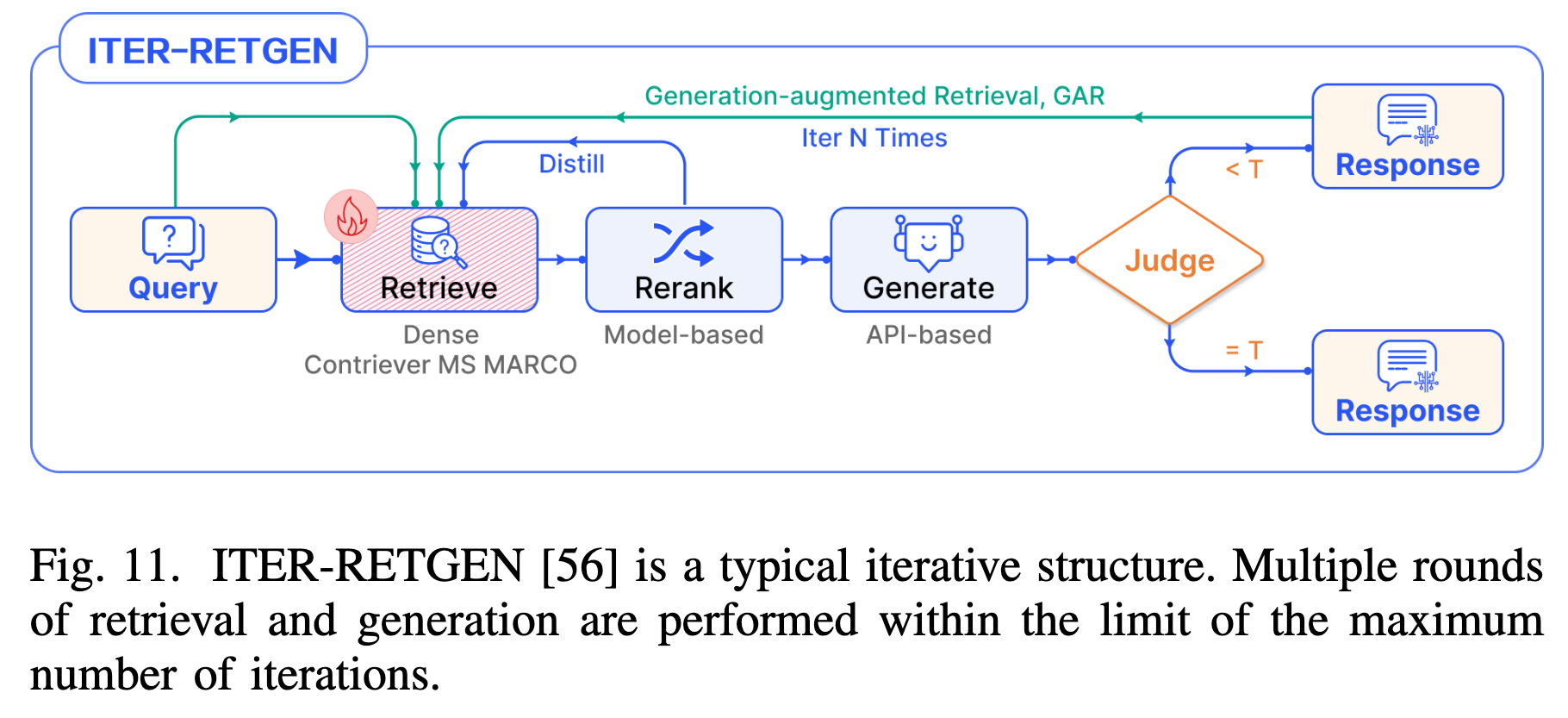
- Iterative Retrieval (迭代检索)
- 机制:固定次数的循环。利用上一轮的生成结果作为上下文,辅助下一轮检索,逐步丰富信息。
- 案例:ITER-RETGEN 交替进行“检索增强生成”和“生成增强检索”。
-
- Recursive Retrieval (递归检索)
- 机制:树状/深度优先的探索。将复杂问题分解,每一轮检索依赖上一轮的输出生成新 Query,层层递进直到满足终止条件。
- 案例:ToC (Tree of Clarifications) 构建澄清树,递归地对模糊问题进行消歧。
-

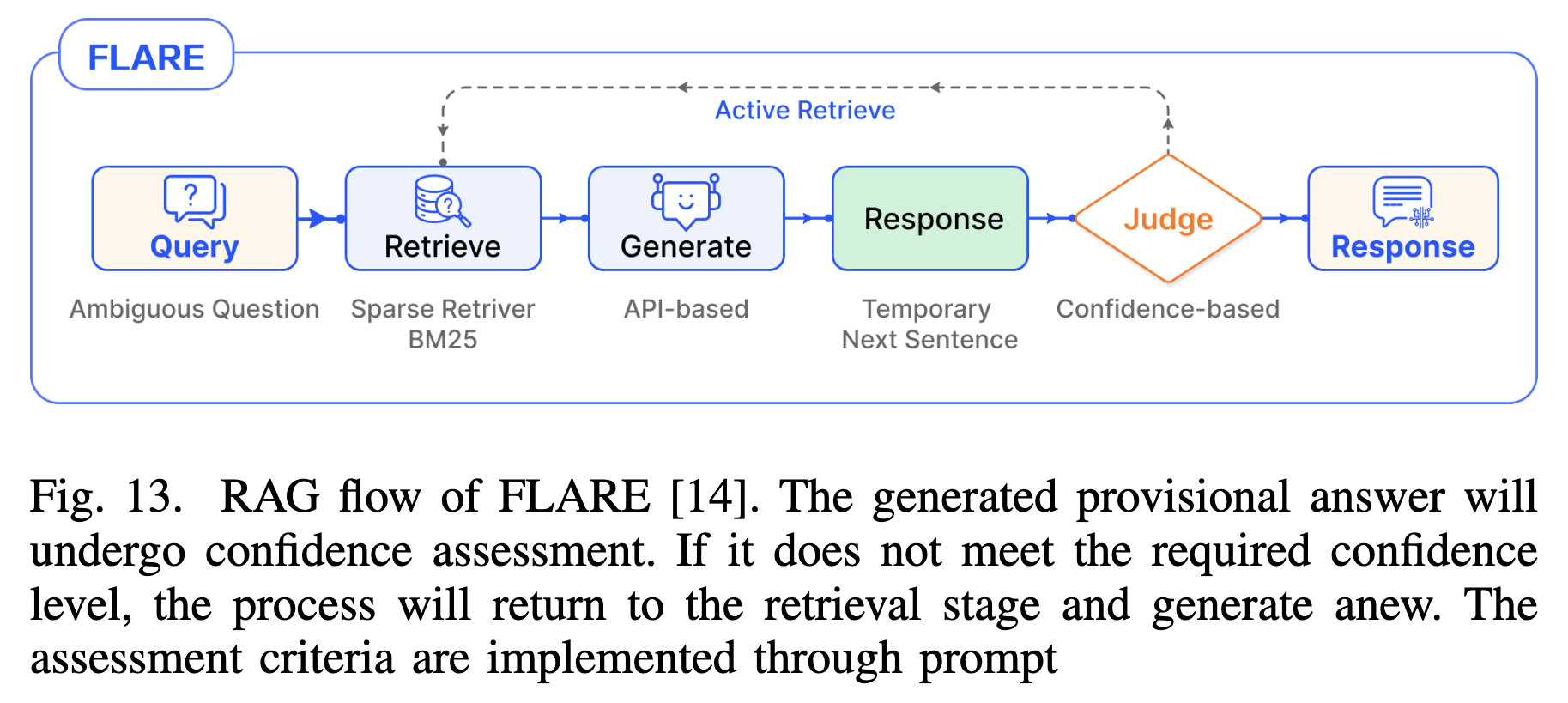
- Adaptive (Active) Retrieval (自适应/主动检索)
- 机制:由 LLM 自主控制。系统没有固定的检索时机,而是由 LLM 在生成过程中动态判断“现在是否需要检索”。
- 案例:
- FLARE:生成过程中监测 Token 的置信度,如果过低则主动触发检索以修正内容。
-
- Self-RAG:训练 LLM 生成特殊的 Reflection Tokens (如
Retrieve,IsRel,IsSup),像人类一样自省并控制流程(检索、评估、生成)。 -
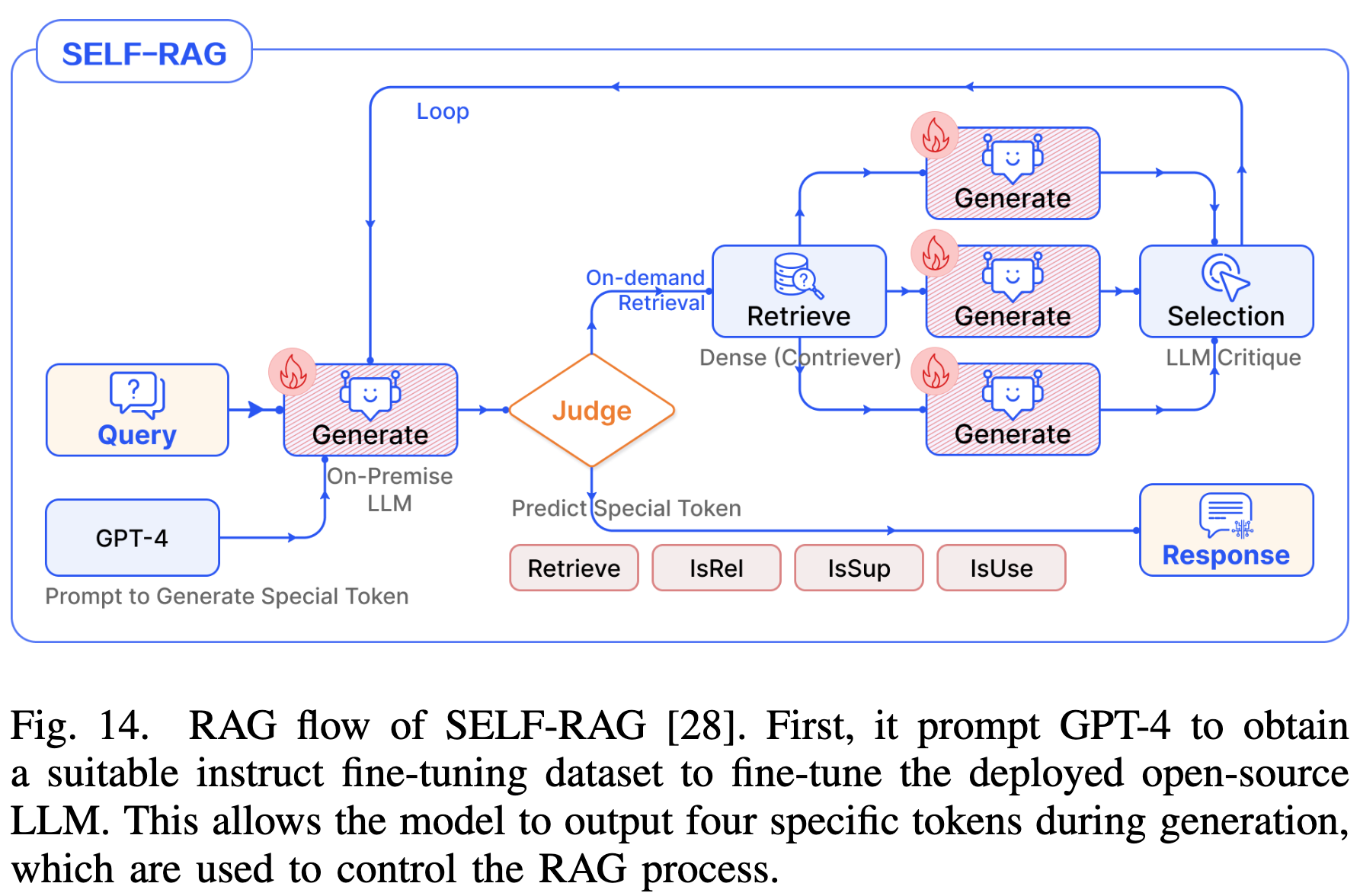
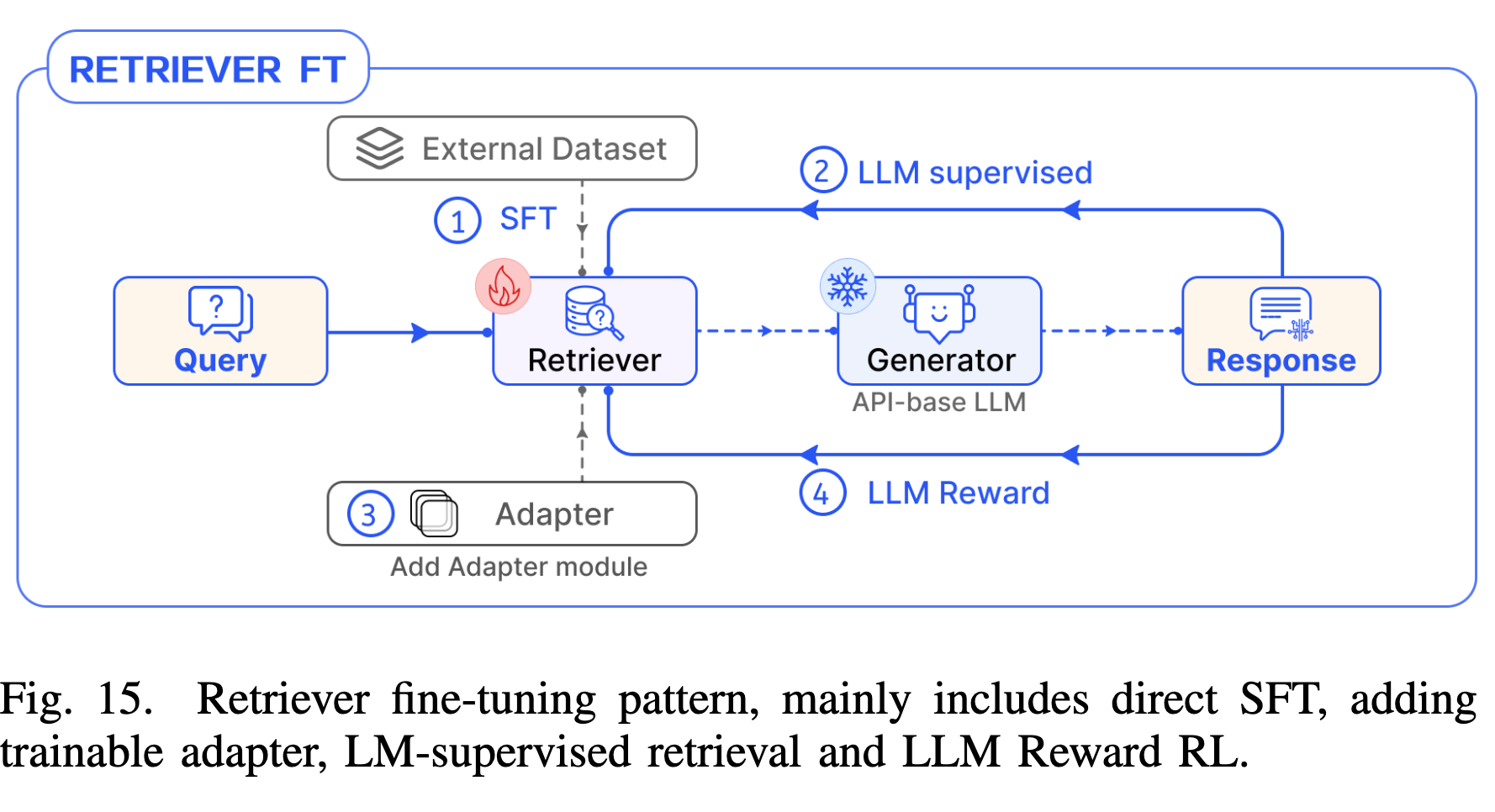
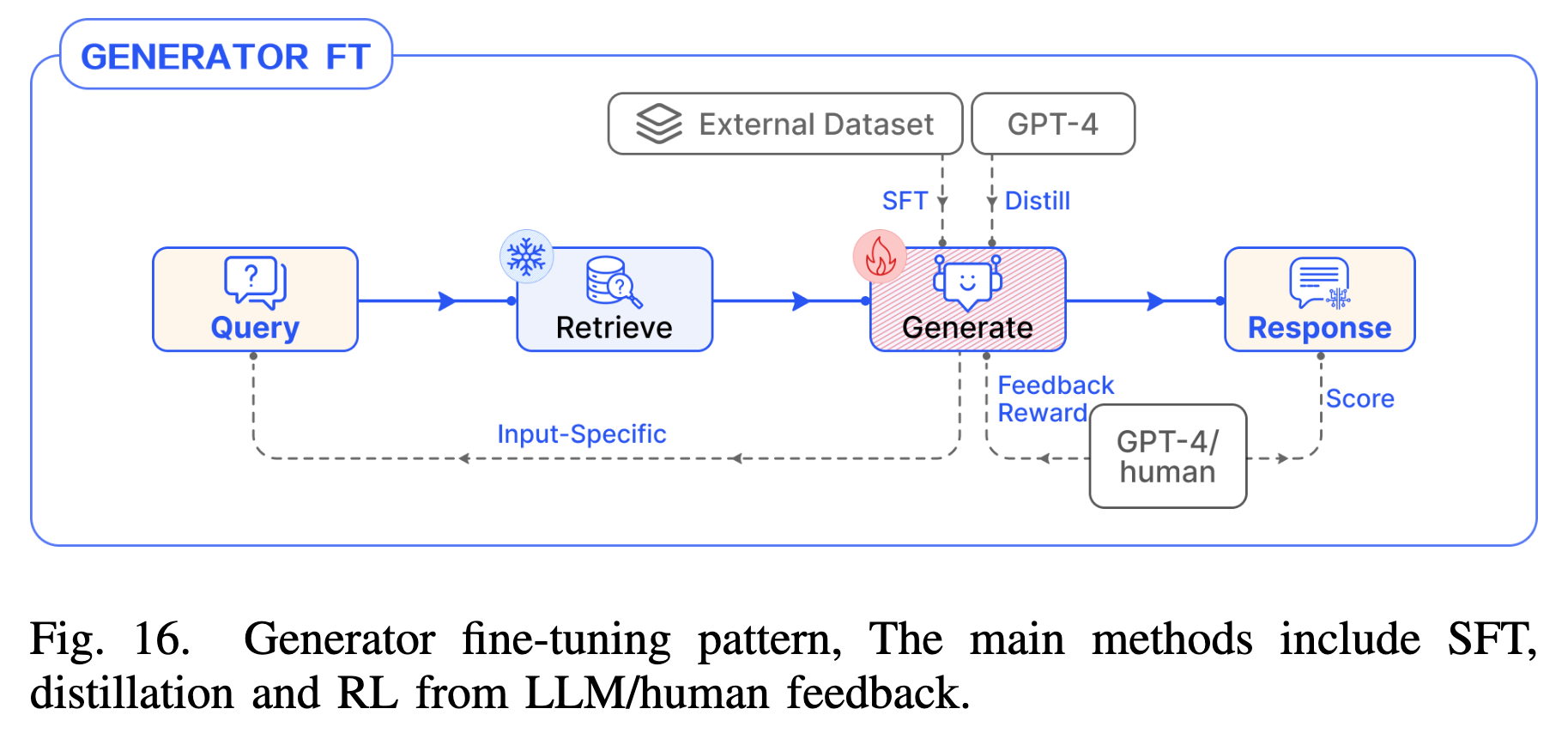
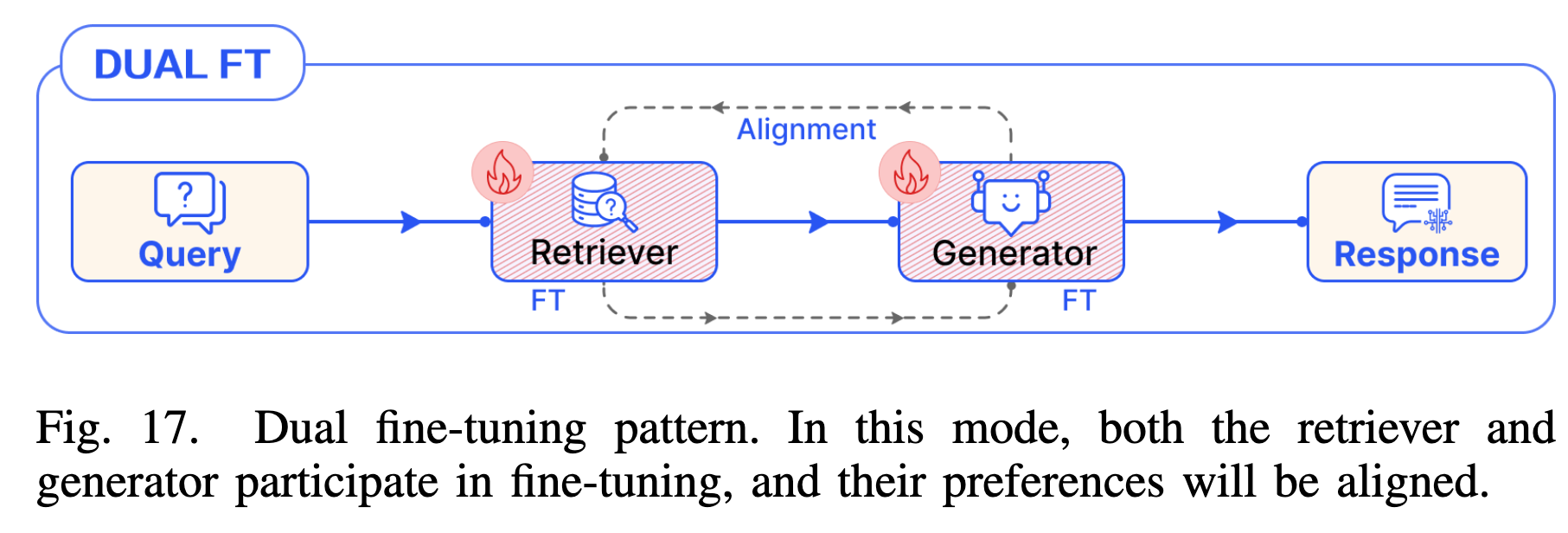
4.5 Tuning Pattern (微调模式)
在 Modular RAG 中,组件是可以被训练的。
- Retriever FT:使用 SFT 或 LM 监督信号优化 Embedding 模型。
- Generator FT:通过指令微调让 LLM 适应特定的输入输出格式(如 JSON)或风格。
- Dual FT:同时微调检索器和生成器(如 RA-DIT),使两者的偏好对齐(Alignment)。
5 扩展性讨论
Modular RAG 框架展示了极强的扩展性,作者通过三个层次展示了如何利用该框架“搭建”新系统:
- 现有模块的重组 (Recombination)
- 案例 (DR-RAG):不发明新算子,而是将检索模块拆分为两个阶段,并结合分类器算子,解决多跳问答问题。
- 引入新流而不引入新算子 (New Flow)
- 案例 (PlanRAG):引入“规划 (Planning)”阶段。利用现有的检索和生成算子,但编排了一个“先规划-再检索-再判断”的复杂逻辑流。
- 引入新算子 (New Operator)
- 案例 (Multi-Head RAG):设计了全新的检索算子,利用 Transformer 的 Multi-Head Attention 激活值作为检索键(Key),以捕获数据的多面性。
思考
模块化的代价
- 延迟 (Latency):Loop 和 Branching 模式显著增加了端到端的推理时间。特别是像 Self-RAG 或 FLARE 这种高频触发检索的模式,在实时应用中可能面临性能瓶颈。
- 错误传播 (Error Propagation):在 Recursive 或 Iterative 模式中,早期的错误检索或生成可能会在循环中被放大。这突出了 Verification (验证) 模块的重要性。
Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks