StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration |
| 作者 | Panwen Hu, Jin Jiang, Jianqi Chen, Mingfei Han, Shengcai Liao, Xiaojun Chang, Xiaodan Liang |
| 机构 | Mohamed bin Zayed University of Artificial Intelligence |
| 来源 | 2024 arXiv: 2411.04925v |
| 总结 | 通过多智能体协作框架及定制化生成技术实现高一致性的定制化故事视频生成 |
摘要
人工智能生成内容(AIGC)的出现推动了自动视频生成的研究,旨在简化传统制作流程。然而,自动化故事视频制作,特别是针对定制化叙事,由于在镜头之间保持主体一致性的复杂性,仍然具有挑战性。现有的方法(如 Mora 和 AesopAgent)虽然集成了多个智能体进行故事到视频(S2V)的生成,但在保持主角一致性和支持定制化故事视频生成(CSVG)方面存在不足。 为了解决这些限制,本文提出了 StoryAgent,这是一个专为 CSVG 设计的多智能体框架。StoryAgent 将 CSVG 分解为分配给专门智能体的不同子任务,模拟专业的制作流程。值得注意的是,该框架包括负责故事设计、分镜生成、视频创作、智能体协调和结果评估的智能体。利用不同模型的优势,StoryAgent 增强了对生成过程的控制,显著提高了一致性。具体而言,我们引入了一种定制的图像到视频(I2V)方法 LoRA-BE,以增强镜头内的时序一致性,同时提出了一种新颖的分镜生成流水线,以保持镜头间的主体一致性。广泛的实验表明,该方法在合成高度一致的故事视频方面有效,优于现有的最先进方法。
内容
1 引言 & 背景 & 相关工作
人工智能生成内容(AIGC)虽然在单镜头视频生成上取得了巨大进展,但在**定制化故事视频生成(CSVG, Customized Storytelling Video Generation)**领域仍面临严峻挑战。CSVG 要求不仅要生成流畅的视频,还要在多镜头叙事中保持主角(Protagonist)形象的高度一致性。
1.1 现有方法的局限性
目前的解决方案主要分为两类,但都存在明显缺陷:
- 基于 Agent 的系统(如 Mora, AesopAgent):
- 通过整合多个 API(T2I, I2V)来生成视频。
- 问题:缺乏对“主角一致性”的专门控制。生成的视频往往每一镜的主角长得都不一样(Inter-shot inconsistency)。
- 定制化生成模型(如 DreamVideo, Magic-Me):
- 通过微调模型来学习特定角色的 ID。
- 问题:在复杂叙事场景下,难以兼顾“角色保真度”和“场景多样性”。要么角色崩坏,要么背景单一。
1.2 本文的切入点
作者认为,单一模型难以同时解决剧本创作、分镜设计和视频生成的一致性问题。因此,本文提出了 StoryAgent,一个多智能体协作框架。
作者的核心观察是:要实现高质量的 Storytelling,必须将“镜头间的一致性”(Inter-shot)和“镜头内的一致性”(Intra-shot)解耦处理。前者通过分镜生成的重绘机制解决,后者通过改进的 I2V 模型解决。
2 StoryAgent 框架设计
StoryAgent 模拟了人类影视制作的流水线,包含五个核心智能体(Agent),由 Agent Manager 统一调度。
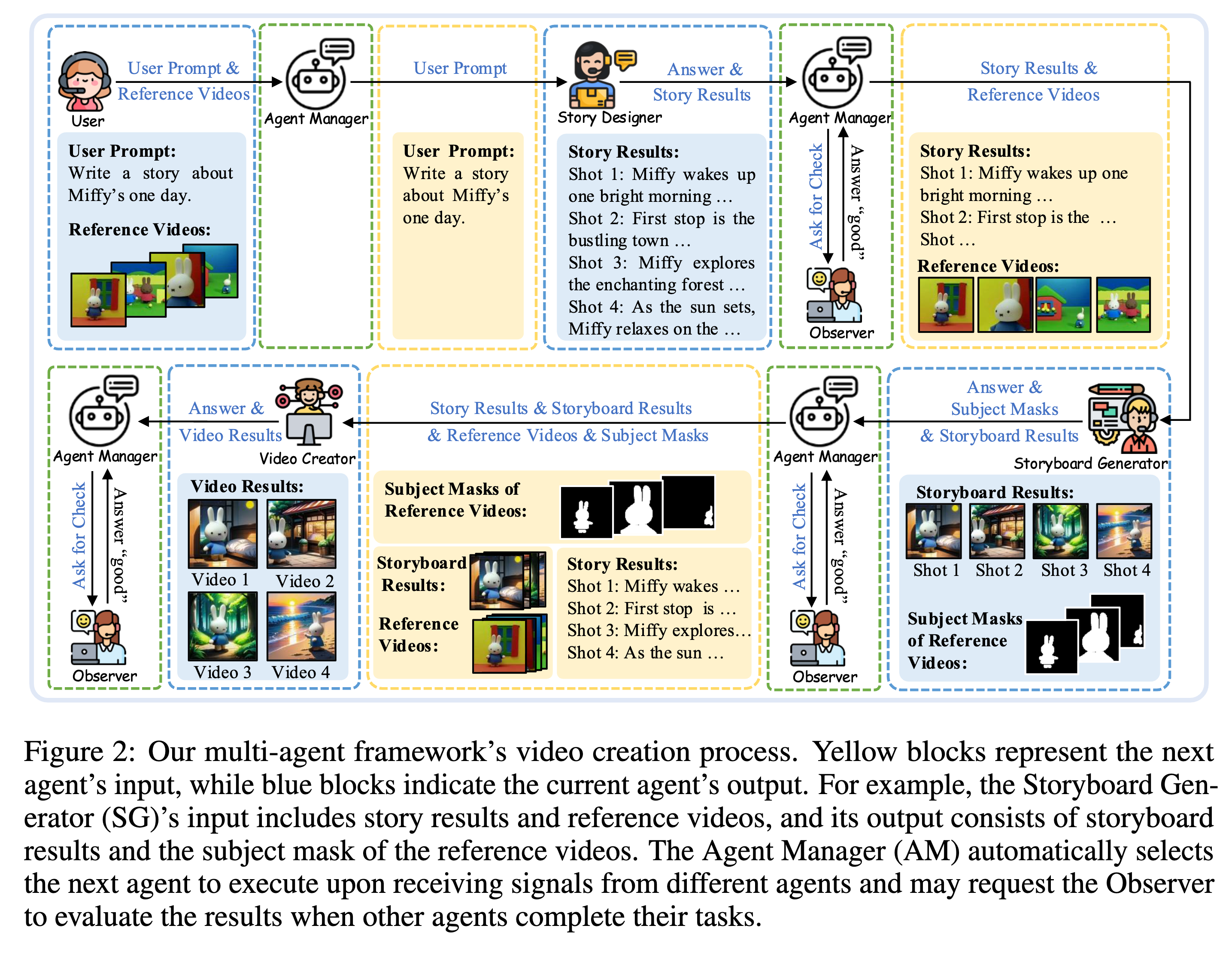
2.1 智能体角色定义
- Agent Manager (AM):
- 基于 LLM (如 GPT-4, Llama) 的中控。
- 负责解析上下文,决定下一个激活哪个 Agent,并传递数据。
- Story Designer (SD):
- 负责剧本创作。将简短的 User Prompt 扩展为详细的分镜脚本 $p={p_1, …, p_N}$。
- 明确每一镜的背景、主角动作和镜头语言。
- Storyboard Generator (SG):
- 职责:生成静态的分镜图像序列。这是保证镜头间一致性的关键步骤。
- 具体实现见下文第 3 章。
- Video Creator (VC):
- 职责:将静态分镜转化为动态视频。这是保证镜头内一致性的关键步骤。
- 核心使用了本文提出的 LoRA-BE 方法。
- Observer (OB):
- 职责:质量控制。对生成结果进行评分,决定是“通过”还是“打回重做”。
- 实现:作者尝试了 GPT-4o, Gemini 等多模态大模型,发现效果不佳(无法准确区分生成质量),最终采用了 LAION aesthetic predictor 作为评分工具。
Observer 的设计虽然在逻辑上构成了闭环(Feedback Loop),但在实验部分作者也承认目前的自动化评估(AQA)还不够成熟,这部分在实际应用中目前更多是“锦上添花”或由人类替代。
3 核心技术实现
为了解决一致性问题,作者并没有直接调用现成的 API,而是重新设计了分镜生成和视频生成的内部逻辑。
3.1 Storyboard Generator:基于“擦除-重绘”的一致性流水线
为了在不同分镜中保持主角长相完全一致,作者放弃了纯 Text-to-Image 的生成方式,转而采用 Generation-Removal-Redrawing 的策略。
- 初始生成 (Initial Generation):
- 使用 StoryDiffusion 等模型根据文本描述生成初始分镜序列 $S={s_1, …, s_N}$
- 此时图像大概率与用户指定的参考主角 $V_{ref}$ 不一致。
- 主体移除 (Subject Removal):
- 使用 LangSAM (Language Segment-Anything Model) 检测并分割出画面中的主角,得到掩码 $M$。
- 重绘注入 (Redrawing with StoryAnyDoor):
- 基于 AnyDoor (一种 Zero-shot 图像定制化方法) 进行改进。
- 将参考主角图 $V_{ref}$ 填补到被挖空的区域中。
- 为了适应多镜头,作者使用参考视频微调了 AnyDoor,使其更擅长处理特定角色的多角度重绘。
这种 Pipeline 的逻辑非常巧妙:利用 T2I 强大的构图能力生成背景和姿态,利用 Segmentation 挖掉不准的人脸,再利用 Inpainting 强行填入正确的主角 ID。这比单纯训练一个 Concept Lora 要稳定得多。
3.2 Video Creator:LoRA-BE 定制化 I2V 生成
将分镜动起来时,现有的 I2V 模型(如 SVD, DynamiCrafter)往往会让主角在运动中变形。为此,作者提出了 LoRA-BE (Block-wise Embeddings)。
- 基线模型:DynamiCrafter (基于 Video Diffusion)。
- 改进 1:LoRA (Low-Rank Adaptation)
- 在 Attention 层引入可训练参数 $A, B$,调整投影矩阵 $W’ = W + BA$。
- 目的:将模型的生成域迁移到特定主角的风格域。
- 改进 2:Block-wise Token Embeddings (核心创新)
- 传统的 Text Inversion (TI) 训练一个全局共享的 token embedding (如
<sks>)。 - LoRA-BE 认为 U-Net 的不同层级(深层/浅层)负责不同的视觉特征。因此,为 U-Net 的 16 个 Cross-attention 模块分别训练独立的 token embedding $e \in \mathbb{R}^{16 \times d}$。
- 这使得模型能更精细地捕捉主角在不同抽象层级上的特征。
- 传统的 Text Inversion (TI) 训练一个全局共享的 token embedding (如
- 改进 3:Localization Loss
- 为了防止过拟合背景,引入损失函数 $\mathcal{L}_{loc}$,强制 Cross-attention map 只关注主角所在的区域(由 Mask $m$ 指导)。
$$\mathcal{L} = \mathcal{L}{ldm} + \mathcal{L}{loc}$$
Block-wise 的设计直觉在于:浅层网络关注纹理细节,深层网络关注语义结构。用同一个 embedding 强行覆盖所有层级不仅难训练,而且容易导致特征冲突。
4 实验评估
4.1 实验设置
- 数据集:
- PororoSV & FlintstonesSV:包含卡通角色的公开数据集,有 Ground Truth (GT) 视频。
- Open-domain:作者从 YouTube 等收集的 8 个新角色(如 Miffy, Kitty),用于测试泛化能力。
- 基线方法 (Baselines):
- SVD (Stable Video Diffusion)
- TI-SparseCtrl (SparseCtrl + Text Inversion)
- DreamVideo, Magic-Me (定制化 T2V 方法)
4.2 定量与定性分析
- 视频质量 (FVD, LPIPS):
- 在 PororoSV 数据集上,StoryAgent 的 FVD (Fréchet Video Distance) 达到 2070.56,显著优于 SVD (2634.01) 和 TI-SparseCtrl (4209.80)。数值越低越好,说明生成的视频分布更接近真实数据。
- 一致性表现:
- SSIM (结构相似性) 提升明显,表明帧间结构保持得更好。
- TI-SparseCtrl 生成的角色在多镜头间忽大忽小,甚至换脸;DreamVideo 经常丢失角色细节。而 StoryAgent 在保持角色衣服、面部特征上表现最佳。

4.3 消融实验 (Ablation Study)
- LoRA-BE 的有效性:
- 对比仅使用标准 Fine-tuning 的 DynamiCrafter,加上 LoRA-BE 后,FVD 进一步降低,且主观视觉上主角的崩坏(Artifacts)明显减少。
- 证明了 Block-wise embedding 在捕捉 Out-of-domain 角色特征时的优越性。
4.4 用户研究 (User Study)
作者组织了用户对五个维度进行打分(1-5分):
- IRC (Inter-shot Consistency): 镜头间一致性。
- IAC (Intra-shot Consistency): 镜头内一致性。
- SBH, TA, OQ: 背景和谐度、文本对齐、整体质量。
- 结果:StoryAgent 在所有指标上均领先,特别是在 IRC (4.6 vs 2.9) 和 IAC (4.8 vs 3.8) 上大幅超越 TI-AnimateDiff 等方法。
思考
- 核心贡献:StoryAgent 并没有发明全新的扩散模型架构,而是通过工程化拆解(Agent Workflow)和针对性微调(AnyDoor重绘 + LoRA-BE)解决了一致性难题。
- Observer 的启示:文中关于 Observer 的实验很有趣(附录 A.5),目前最先进的 MLLM(GPT-4o, Gemini)在判断“两张图哪个分镜更好”或者是“是否和原图一致”时,表现甚至不如基于 CLIP 的简单评分器(LAION)。这提示我们在构建自动化 Agent Loop 时,评估环节可能是最大的瓶颈。
- 局限性:尽管在卡通角色上表现出色,但对于真实人类视频(Customized human videos),由于基座模型的限制,效果仍有待提升。且生成视频时长较短(1-2秒)。
StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration