Patchwork: A Unified Framework for RAG Serving
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | PATCHWORK: A Unified Framework for RAG Serving |
| 作者 | Bodun Hu, Saurabh Agarwal, Luis Pabon, Aditya Akella |
| 机构 | UT Austin |
| 来源 | arXiv 2025 |
| 总结 | 通过模块化的 Python 规范接口、基于最大流的离线资源分配优化以及在线 SLO 违规缓解机制,提升了 RAG 系统的吞吐量并降低了SLO违规 |
摘要
检索增强生成(RAG)已成为一种通过与外部知识源集成来增强大型语言模型(LLM)可靠性的新范式。然而,由于这些系统的计算管道本质上由 LLM、数据库和专用处理组件等异构部分组成,其高效部署面临着重大的技术挑战。我们介绍了 PATCHWORK,这是一个全面的端到端 RAG 服务框架,旨在解决这些效率瓶颈。PATCHWORK 的架构提供了三个关键创新:首先,它提供了一个灵活的规范接口,使用户能够实现自定义的 RAG 管道。其次,它将这些管道部署为分布式推理系统,同时针对单个 RAG 组件的独特可扩展性特征进行优化。第三,PATCHWORK 包含一个在线调度机制,该机制持续监控请求负载和执行进度,通过战略性请求优先级排序和资源自动缩放来动态最小化服务等级目标(SLO)违规。我们对四种不同的 RAG 实现进行的实验评估表明,PATCHWORK 提供了比商业替代方案显著的性能提升,实现了超过 48% 的吞吐量增益,同时减少了约 24% 的 SLO 违规。
内容
1. 引言 & 相关工作
1.1 RAG 服务的核心挑战
RAG 作为解决 LLM 幻觉和知识过时问题的关键范式,其架构已从简单的“检索-生成”演变为包含查询重写、多步检索、条件分支等复杂流程的复合系统。
作者指出,尽管 RAG 应用广泛,但在 高效部署(Serving) 方面仍面临三大系统级挑战,这使得现有的单体模型服务框架难以直接适用:
-
技术栈的快速演进:
RAG 生态系统更新极快(如从文本索引到向量索引,再到图索引),且经常涌现新的组件(如 Guardrails、Rerankers)。这种碎片化导致难以开发通用的性能管理技术,开发者往往受限于定制化的“拼凑”解决方案。 -
组件的异构性:
与单体 LLM 不同,RAG 流水线由多种计算特性的组件组成:- 资源需求异构:Retriever 通常是 CPU/内存密集型(向量数据库),而 Generator 是 GPU 密集型。
- 扩展行为异构:不同组件的延迟随负载(Batch Size)或数据量变化的曲线截然不同。例如,Qdrant 数据库的查询延迟随文档数量增加而显著上升,而 ChromaDB 则相对平稳;vLLM 的吞吐量随 Batch Size 的扩展性优于 Ollama。
-
执行时间的不可预测性:
这是 RAG 与传统深度学习推理最大的区别。由于 RAG 流程中包含基于内容的条件分支(如 Corrective RAG 中若检索质量低则触发 Web Search)和递归调用(如 IRCoT),导致请求的执行时间无法像传统 LLM 那样仅通过输入 Token 长度来准确预测,这使得满足严格的 SLO(服务等级目标) 变得极具挑战性。
这一点非常关键。传统的 ML Serving 往往假设“输入大小决定计算量”,但在 RAG 中,Runtime 是数据依赖的(Data-dependent),这直接否定了传统调度器中很多基于确定性预测的优化假设。
1.2 相关工作与局限性
-
针对 RAG 的系统优化:
- 特定组件优化:如 RALMSpec、SpeculativeRAG 和 TeleRAG,主要关注利用推测执行(Speculation)来加速特定的检索或生成步骤。
- 硬件/架构协同设计:如 PiperRAG 和 Chameleon,针对特定瓶颈进行软硬件优化。
- 局限性:这些大多是“点解决方案”(Point Solutions),要么需要修改 RAG 流水线的逻辑,要么只优化特定瓶颈。一旦流水线结构改变(例如更换了 Retriever),优化可能失效。
- RAGO:作为同期的并发工作,RAGO 虽然也研究了 RAG 的系统优化,但更侧重于分类和抽象,并未解决端到端部署中的动态资源管理和运行时 SLO 缓解问题。
-
通用 ML/LLM 推理服务:
- 系统如 Clipper、Orca、vLLM 和 Sarathi 主要针对单一的、整体的模型进行优化(如 PagedAttention、Continuous Batching)。
- 局限性:它们忽略了 RAG 系统中组件间复杂的交互(如 CPU 与 GPU 组件的协同),以及非 LLM 组件(如数据库、搜索引擎)的异构扩展特性。
Patchwork 的定位:它是第一个端到端的 RAG 服务框架,旨在在不修改用户流水线逻辑的前提下,通过组件级批处理、异构资源分配和运行时 SLO 缓解策略来最大化吞吐量并保证服务质量。
2. 背景 & 动机
2.1 RAG 流水线概览
RAG 系统不仅仅是一个“检索+生成”的简单组合,而是一个包含多个有序组件的复杂流水线。

如图 2 所示,一个典型的 RAG 请求可能经过以下组件:
- Query Indexer/Rewriter:对用户查询进行预处理或重写。
- Retriever:从外部索引数据库(Indexed Knowledge Base)中检索相关文档。
- Augmenter:将检索到的文档与原查询结合,可能涉及总结、排序或过滤。
- Generator (LLM):基于增强后的提示词生成最终回答。
- Post-Processing:对输出进行格式化或安全检查。
这里的关键在于,这些组件不是单一的单体服务,而是由不同的硬件资源驱动,且彼此之间存在数据依赖。
2.2 核心挑战与设计需求
作者认为,要高效服务 RAG 流水线,必须解决以下三个层面的异构性和复杂性:
(1) 生态系统的快速演进 (RAG Evolution)
RAG 组件更新迭代极快,新的检索算法(如 Graph RAG, Tree Index)和生成策略(如 Recursive RAG)层出不穷。
- 现象:Retriever 从简单的文本索引进化为向量、图、位图索引;Augmenter 从简单的拼接进化为基于 LLM 的重排序。
- 痛点:现有的抽象(如 LangChain)往往对底层资源管理封装过死,或者跟不上新特性的发布,导致开发者难以在不牺牲性能的情况下灵活集成新组件。
Requirement 1:系统必须提供模块化接口,允许用户轻松集成新组件或自定义逻辑,同时向用户隐藏底层资源分配的复杂性。
(2) 组件的异构性 (Heterogeneity)
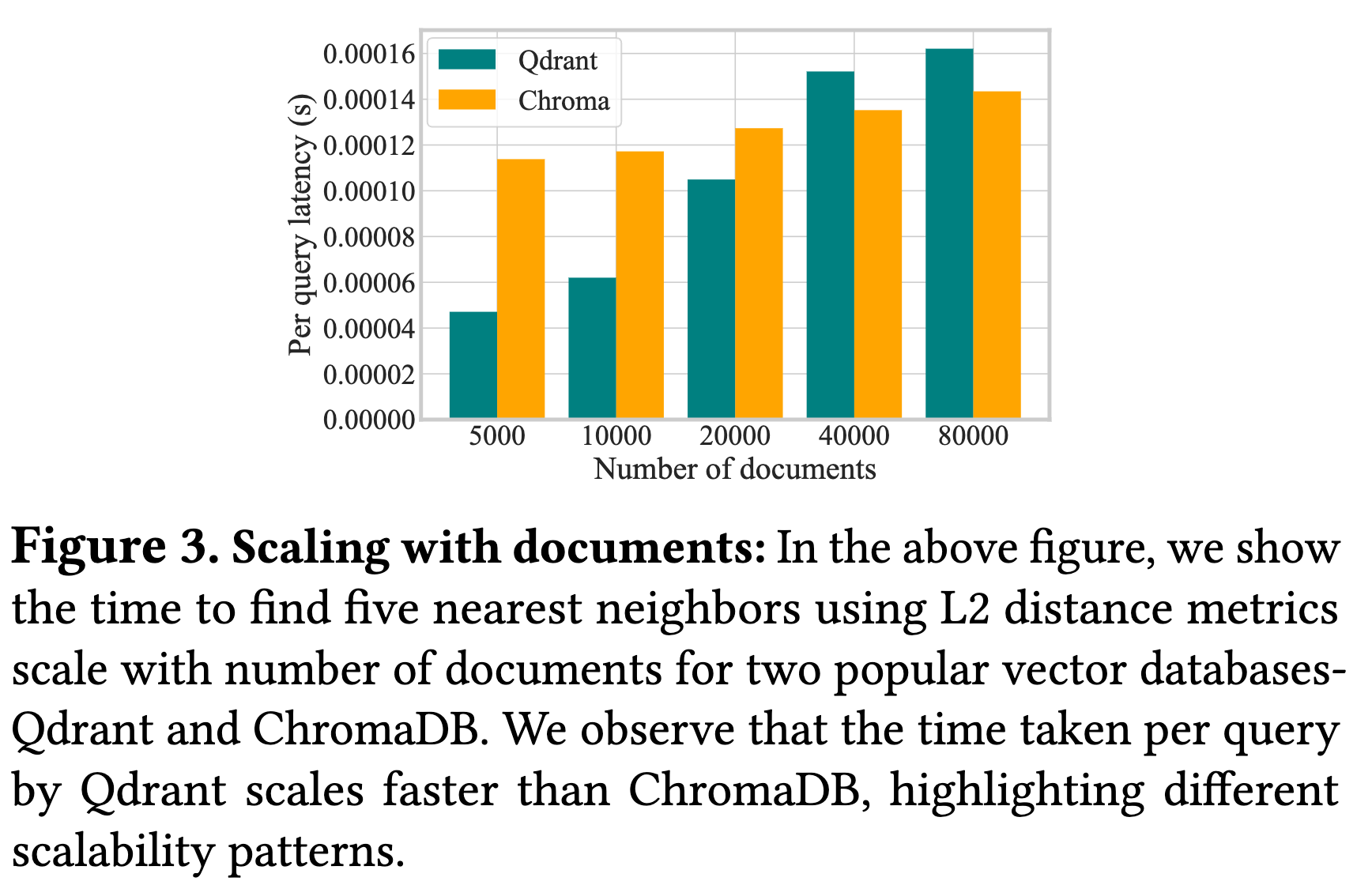
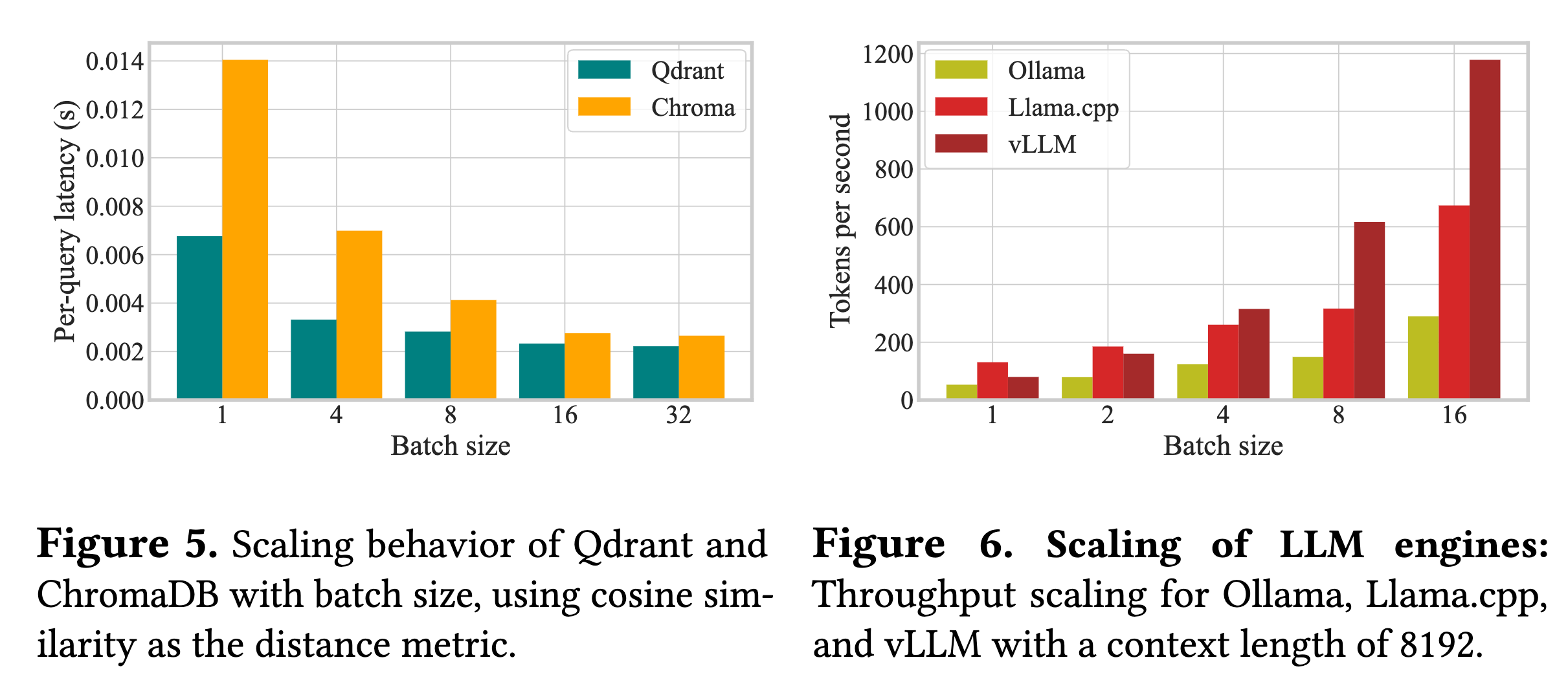
这是本文分析最精彩的部分。作者指出 RAG 组件在资源需求和性能扩展行为上存在巨大的差异。
- 资源异构:Retriever 是 CPU/IO 密集型,Generator 是 GPU 密集型。
- 性能扩展行为异构 (Performance Scaling):即使是同类组件,不同实现的扩展性也完全不同。
- 数据量扩展:如图 3 所示,随着文档数量增加,Qdrant 的延迟显著增加,而 ChromaDB 保持相对平稳。
- Batch Size 扩展:如图 5 和图 6 所示,vLLM 的吞吐量随 Batch Size 增加而大幅提升(线性扩展好),而 Ollama 的提升则非常有限。
Requirement 2:系统必须能感知组件特性,针对开发者选择的具体组件和配置(如模型大小、检索 Top-K),自动寻找吞吐量最大的资源分配和 Batch Size 组合。
为什么这很重要?
作者举了一个极好的例子:假设你有 5 CPU + 2 GPU。
如果你用 Qdrant(低 Batch 扩展性,高计算密度),最优配置可能是分配 3 CPU 给 Retriever(瓶颈所在)。
如果你换成 ChromaDB(高扩展性),瓶颈可能会转移到 Augmenter,此时最优配置变成 1 CPU 给 Retriever,4 CPU 给 Augmenter。
这说明:没有通用的静态资源分配方案。系统必须能“理解”每个组件的特性曲线。
(3) 执行时间的不可预测性 (Unpredictability)
这是 RAG 服务区别于传统 LLM 服务的关键区别。
- 原因:
- 条件执行 (Conditional Execution):例如 Corrective RAG,只有当检索结果被评分模型判定为“不相关”时,才会触发 Web Search 分支。
- 递归逻辑:如 IRCoT 会根据推理过程多次迭代检索。
- 证据:如图 7 所示,RAG 请求的执行时间与输入 Token 长度(Query Length)几乎不相关,呈现出高度的离散分布。这与传统 LLM 服务中“Context Length 决定推理时间”的假设完全相悖。
Requirement 3:由于无法事前准确预测,系统必须具备运行时的动态请求管理能力(Active Runtime Management),以防止长尾请求导致的 SLO 违约。
3. Patchwork 系统设计
Patchwork 采用了一种端到端的设计哲学,旨在向用户隐藏底层分布式系统的复杂性,同时最大化硬件效率。
系统由三个主要组件构成:
- Client Library(客户端库)
- Scheduler(调度器)
- Orchestrator(编排器)

3.1 Intent-Driven 的 RAG 规范接口
为了应对 RAG 技术栈快速演进 的挑战,Patchwork 拒绝使用复杂的领域特定语言(DSL),而是选择拥抱原生 Python。
- Pythonic Design:用户只需使用标准的 Python 类来定义组件(如
class Grader(VLLM)),并使用装饰器@harmonia.make标记推理函数。 - 自动图捕获 (Graph Capture):利用 Python 的
PEP 523帧评估 API(Frame Evaluation API),Patchwork 可以在运行时拦截函数调用,自动提取计算图(Computational Graph)。- 优势:这种设计让用户感觉像是在写单机脚本,但实际上 Patchwork 在后台将其转换为分布式执行计划。这也意味着用户可以随意引入第三方库或自定义逻辑,而无需等待框架适配。
作者在这里做了一个很棒的类比:这就像 PyTorch 不需要为每种新的数学运算都重新发明一种模块一样,Patchwork 也不限制用户使用什么样的 RAG 组件。
3.2 离线阶段:资源分配与配置选择
针对组件异构性,Patchwork 在部署前引入了一个离线优化阶段。其核心目标是:在不改变用户设定的影响准确率的参数(如 Top-k, Model Size)的前提下,通过调整 资源分配(Resource Allocation) 和 Batch Size 来最大化系统吞吐量。
(1) 问题建模:最大并发流 (Max-flow Formulation)
作者将资源分配问题建模为有向图上的最大并发流问题。
- 目标:最大化整个流水线的瓶颈吞吐量(即最大化 $min_{\forall i \in N}$)。
- 决策变量:
- $a_{i,k}$:分配给组件 $i$ 的 $k$ 类型资源数量(如 GPU 数量)。
- $b_{i,k}$:组件 $i$ 在 $k$ 类型节点上的 Batch Size。
- 约束条件:
- 资源总量约束(不超过集群总资源)。
- 流量守恒(下游处理能力必须覆盖上游输出)。
- 内存/显存限制(Batch Size 不能爆显存)。
(2) 性能画像 (Scalable Profiling)
为了求解上述问题,必须知道每个组件的性能模型 $T_i(b_{i,k}, a_{i,k})$。
- 挑战:穷举所有 Batch Size 进行测试太慢。
- 优化:Patchwork 利用分段线性近似 (Piecewise Linear Approximation)。它通过二分查找(Binary Search)采样几个关键点的性能,然后拟合出分段线性函数。
- 结果:这使得复杂的非线性优化问题可以转化为混合整数线性规划 (MILP),从而使用 Gurobi 快速求解。
3.3 在线阶段:最小化 SLO 违约
针对 执行时间的不可预测性,Patchwork 在运行时引入了主动的 SLO 缓解机制。
(1) 违约检测 (Violation Detection)
系统需要预判一个正在运行的请求是否会超时。作者对比了两种预测器:
- XGBoost:使用查询长度、中间结果大小、已用时间等特征。
- Running Average Estimator(滑动平均):仅基于当前组件的历史平均运行时间。
- 结论:实验发现两者准确率相差无几(图 10),但滑动平均开销极低且无需训练,因此 Patchwork 默认采用滑动平均估计器。
(2) 缓解策略 (Mitigation Strategies)
一旦检测到某个请求有 SLO 违约风险(Expected Remaining Time + Elapsed Time > SLO),调度器会采取分级措施:
- 请求优先 (Request Prioritization):该请求被标记为高优先级,插队调度,跳过常规队列。
- 背压 (Backpressure):暂时停止接受新请求,直到风险解除,防止系统雪崩。
- 自动扩缩容 (Auto-scaling):利用 Orchestrator 动态增加瓶颈组件的实例数(如果集群有空闲资源)。
这种机制实际上是在吞吐量和延迟达标率之间做权衡。通过优先处理“濒死”请求,可能会产生流水线气泡(Bubbles),稍微降低整体吞吐,但能显著减少 SLO 违约。
4. 实验
4.1 实验设置与基准
- 硬件环境:使用 4 台服务器,每台配置双路 Intel Xeon Silver 4314 CPU 和 8 张 NVIDIA A100 (80GB) GPU。
- 数据集:
- 查询集:从 LMSYS-Chat-1M 中采样的 3000 条对话。
- 检索库:从 C4 数据集中抽取的 50,000 条新闻文档。
- 测试负载:选取了四种具有代表性的 RAG 应用,涵盖了从简单反馈循环到复杂图检索的多种模式:
- CRAG (Corrective RAG):包含评分(Grading)和条件 Web 搜索。
- MemoRAG:基于记忆模型的全局理解。
- IRCOT:交错式检索与思维链推理。
- HippoRAG:基于海马体索引理论的图检索。
- 基准对比 (Baselines):
- 对于 CRAG,对比商业级框架 LangGraph。
- 对于其他应用,对比作者提供的原生实现(通常是串行的或简单的并行)。
4.2 吞吐量表现 (Throughput)
实验结果表明,Patchwork 在所有场景下均取得了显著的吞吐量提升。
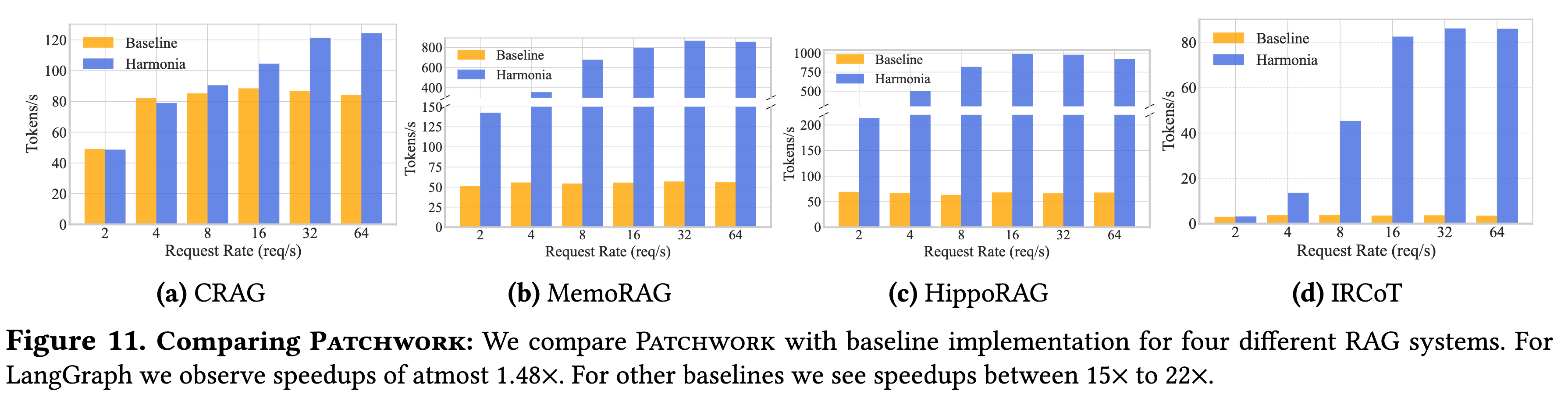
(1) 针对 LangGraph 的提升 (CRAG)
- 结果:在高负载下,Patchwork 比 LangGraph 提升了 1.48x 的吞吐量。
- 瓶颈分析:
- 在 CRAG 流程中,Grader 组件(使用 LLM 评估检索相关性)计算量巨大,成为系统的主要瓶颈。
- LangGraph 采用均匀的资源分配,无法解决此瓶颈。
- Patchwork 的解法:优化器识别出瓶颈后,自动将 4 个 GPU 分配给 Grader,而 Transformer 和 Generator 各只分配 1 个 GPU。这种非对称的资源分配成功打通了流水线。
(2) 针对原生实现的提升 (MemoRAG, HippoRAG, IRCOT)
- 结果:提升幅度惊人,分别达到 15x, 14x, 22x。
- 归因分析 (Ablation Study):作者通过逐步开启优化选项,量化了各技术的贡献(以 MemoRAG 为例,见图 12b):
- 组件级批处理 (Batching):贡献最大,带来了 9.6x 的提升。
- 流水线并行 (Pipelining):带来 1.5x 提升。
- 资源分配 (Resource Allocation):进一步带来 1.78x 提升。
这组数据非常有说服力。它揭示了现有的 RAG 实现大多还在“石器时代”(串行、单请求处理),只要引入经典的系统级优化(批处理、流水线),就能获得数量级的性能飞跃。
4.3 SLO 违约缓解与 Trade-off
Patchwork 不仅关注“跑得快”(吞吐量),还关注“跑得稳”(SLO 达标率)。
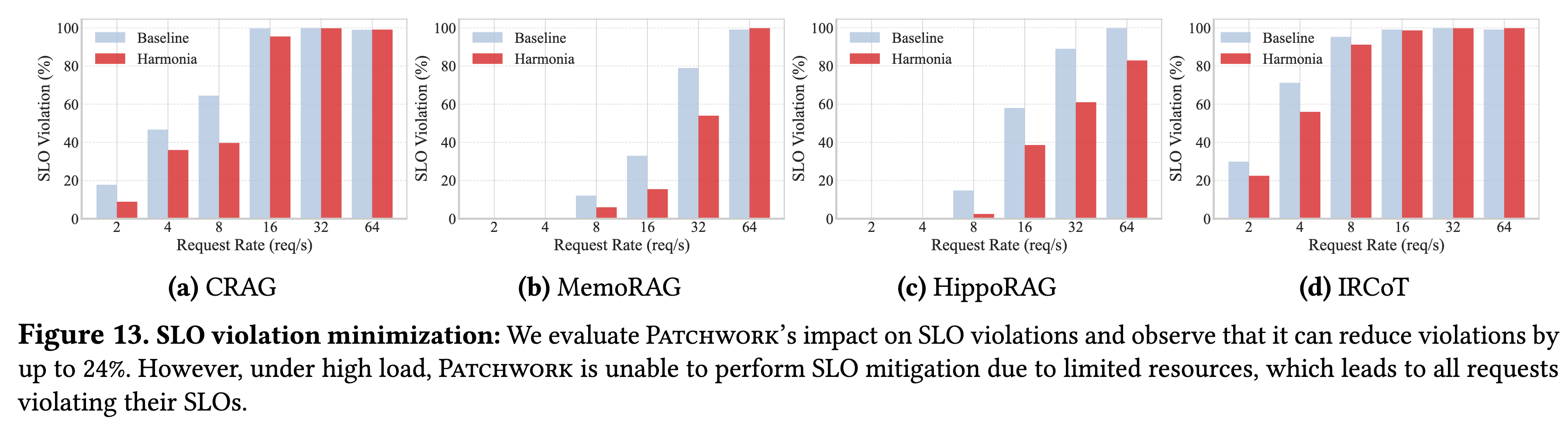
-
效果:在中等负载下,开启运行时 SLO 缓解机制可将违约率降低约 24%。
-
代价 (The Cost of QoS):
- 为了抢救即将超时的请求,调度器会进行非顺序调度 (Out-of-order Scheduling),优先处理高危请求。
- 这会破坏原本完美的流水线节拍,产生计算空隙(Bubbles)。实验显示,开启该功能可能导致整体吞吐量下降 16%(图 14)。
-
这是一个典型的系统设计权衡:Patchwork 允许用户用一部分吞吐量去“购买”更高的延迟确定性。
-
自动扩缩容 (Auto-scaling):
- 图 15 展示了一个生动的案例:在检测到 CRAG 的 Grader 组件即将导致大面积违约时,系统自动上线了一个新的 GPU 节点。
- 整个过程零停机,吞吐量曲线在短暂波动后迅速回升到更高水平。
4.4 敏感度与扩展性
- Batch Size 的选择:
- Patchwork 推荐的 Batch Size 并非总是越大越好。实验表明,使用优化器计算出的“甜点”配置(Sweet Spot),比盲目使用最大显存 Batch Size 的性能高出 31.6%。这是因为过大的 Batch Size 会增加单次推理延迟,可能导致下游组件饥饿。
- 调度器性能:
- 即使在 1024 req/s 的超高并发下,中心化调度器的处理延迟仍稳定在 2ms 左右(图 17)。
- Gurobi 求解器在 512 节点 的规模下,优化耗时仅需 3秒,证明了该方案在动态云环境中的可行性。
Patchwork: A Unified Framework for RAG Serving