UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist |
| 作者 | Zhengyang Liang, Daoan Zhang, Huichi Zhou, Rui Huang, Bobo Li, Yuechen Zhang, Shengqiong Wu, Xiaohan Wang, Jiebo Luo, Lizi Liao, Hao Fei |
| 机构 | Singapore Management University, University of Rochester, University College London, NUS, CUHK, Stanford University |
| 来源 | 2024 arXiv: 2406.04325v |
| 总结 | 提出了一个开源的全能型多智能体框架 UniVA,利用“规划-执行”双智能体架构和基于 MCP 的工具链,统一了视频理解、生成、编辑等任务,解决复杂长程视频工作流问题。 |
摘要
虽然专用的 AI 模型在孤立的视频任务(如生成或理解)上表现出色,但现实世界的应用往往需要结合这些能力的复杂迭代工作流。为了弥补这一差距,我们推出了 UniVA,这是一个面向下一代视频通用工具(Video Generalist)的开源、全能多智能体框架,它将视频理解、分割、编辑和生成统一到了连贯的工作流中。 UniVA 采用 “规划-执行”(Plan-and-Act)双智能体架构 来驱动高度自动化和主动的工作流:
* 规划智能体(Planner Agent):解释用户意图,并将其分解为结构化的视频处理步骤。
* 执行智能体(Executor Agent):通过模块化的、基于 MCP(Model Context Protocol) 的工具服务器(用于分析、生成、编辑、追踪等)来执行这些步骤。
通过分层多级记忆(Hierarchical Multi-level Memory)——包含全球知识、任务上下文和用户特定偏好——UniVA 维持了长程推理能力、上下文连续性以及用户个性化。
为了全面评估 UniVA,我们提出了 UniBench,这是一个包含 745 个复杂多步骤查询的基准测试,涵盖生成、理解、编辑及其组合任务。实验表明,UniVA 在处理复杂视频任务方面显著优于现有的专有模型(如 Claude 3.5 Sonnet 和 GPT-4o),确立了其作为视频领域多功能且强大的开源助手的地位。
内容
1 引言 & 相关工作
本章节旨在阐明 UniVA 诞生的背景、当前视频领域面临的核心痛点以及 UniVA 在现有研究版图中的定位。
1.1 背景
尽管人工智能在视频领域取得了显著进展,但目前的生态系统呈现出高度碎片化的特征:
- 能力孤岛 (Isolated Capabilities):
- 视频生成 (Generation):模型如 Sora, Gen-3, LTX-Video 等在生成逼真视频方面表现出色,但往往缺乏对物理规律的深度理解或精确的指令遵循能力。
- 视频理解 (Understanding):模型如 InternVideo, Video-LLaMA 擅长描述和问答,但无法主动修改或创造内容。
- 复杂工作流的缺失 (Workflow Gap):
- 现实世界的应用需求往往是迭代且复合的。例如:“分析这段视频中人物的动作,将其修改为另一种动作,并保持背景不变”。
- 这种任务需要 理解 -> 分割 -> 编辑 -> 生成 的闭环,而目前的单一模型无法胜任,用户需要在多个工具间手动切换。
- 闭源与封闭 (Closed-Source Nature):
- 顶级模型(如 GPT-4o, Claude 3.5 Sonnet 的视频能力)通常是闭源的,不仅限制了社区的二次开发,也难以通过 API 进行细粒度的工具集成。
核心冲突:现有的 Video AI 模型是强大的“工具”,但缺乏一个能像人类一样熟练使用这些工具组合来解决复杂问题的“工匠”(Agent)。
1.2 相关工作与局限性
作者将现有的研究分为以下几个流派,并指出了它们的局限性,从而引出 UniVA 的设计必要性:
1.2.1 视频生成与编辑模型 (Video Generation & Editing Models)
- 现状:领域内涌现了大量扩散模型(Diffusion Models)和 Transformer 模型。
- Text-to-Video (T2V): LTX-Video, Wan, CogVideoX。
- Video Editing: Runway Gen-2/3, Kling。
- 局限:这些模型通常是单次传递 (Single-pass) 的黑盒。如果生成结果有瑕疵(例如手部崩坏),用户很难通过自然语言进行精确的局部修正,只能重新抽卡。
1.2.2 视频理解与多模态大模型 (Video Understanding & Video-LLMs)
- 现状:Video-LLaMA, LLaVA-Video 等模型将视频映射到 LLM 的特征空间,实现了视频问答。
- 局限:它们主要是被动的观察者。它们可以“看懂”视频,但无法“行动”(Act),即无法调用工具来改变视频内容或获取外部信息。
1.2.3 现有的视频智能体 (Existing Video Agents)
- 现状:近期出现了一些尝试将 LLM 作为控制器来处理视频任务的工作(如 ViperGPT, HuggingGPT)。
- 局限:
- 缺乏统一标准:工具接口各异,难以扩展。
- 规划能力弱:往往只能执行简单的线性链条,缺乏长程规划(Long-horizon Planning)和错误恢复机制。
- 记忆缺失:无法在多轮交互中记住用户的个性化偏好或复杂的上下文信息。
1.3 UniVA 的定位 (UniVA’s Position)
针对上述问题,UniVA 被定位为首个开源的、全能型 (Omni-capable) 视频智能体框架。它不仅仅是一个模型,而是一个操作系统级的解决方案:
- 统一性 (Unification):在一个框架内打通理解、生成、分割、编辑。
- 双智能体架构 (Dual-Agent):引入 Planner 和 Executor 分离设计,模拟人类的“三思而后行”。
- 标准化 (Standardization):利用 MCP (Model Context Protocol) 协议,使得接入新的视频工具(Tools)像安装插件一样简单。
- 基准测试 (Benchmarking):填补了复杂视频任务评估的空白(UniBench)。
2 UniVA Framework
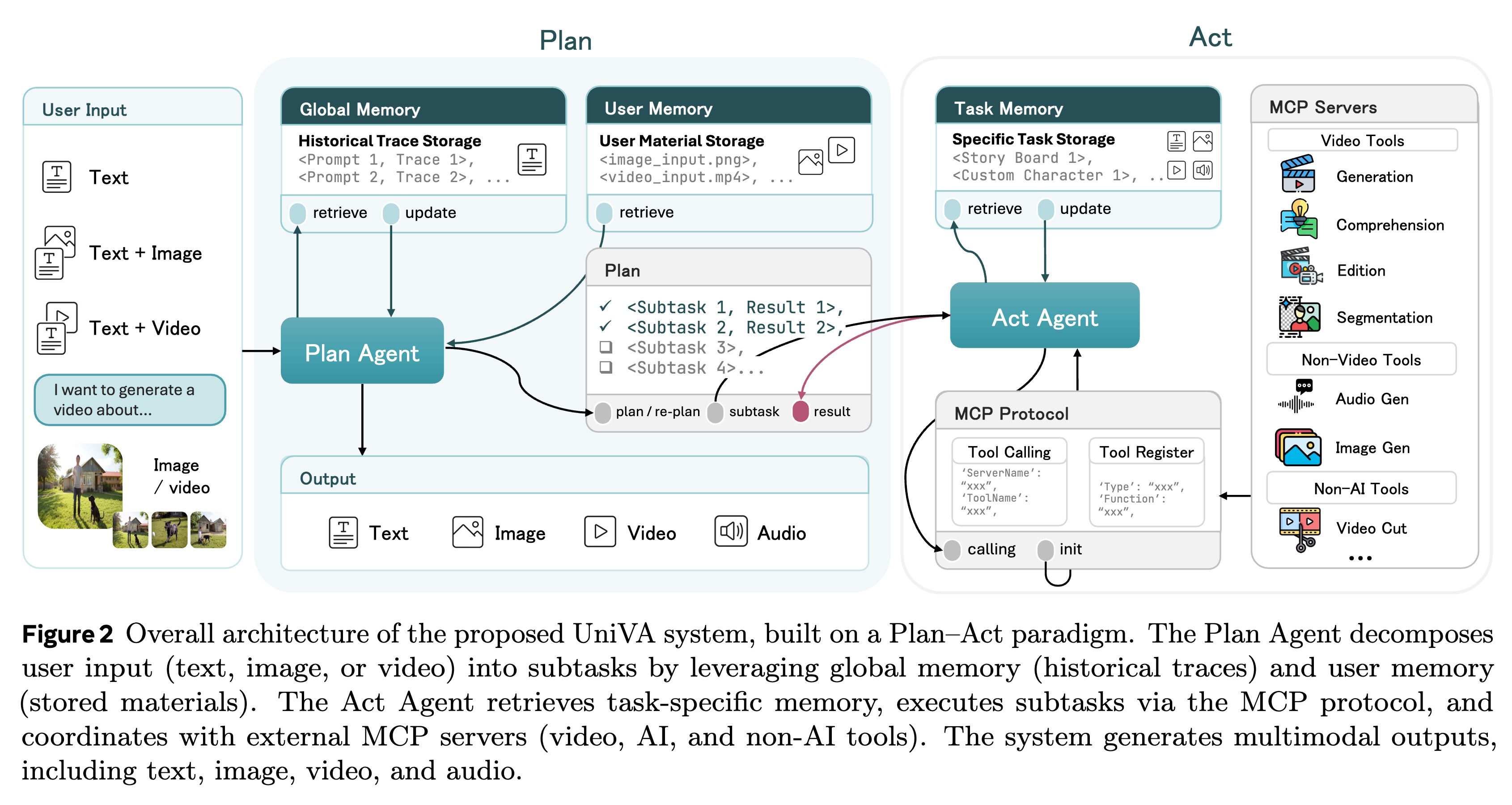
UniVA 的核心设计哲学是去中心化与模块化。它并没有试图训练一个端到端的“超级模型”,而是构建了一个类似操作系统的智能体框架,通过调度不同的 SOTA 专家模型来协同完成任务。
(% asset_img 20251223100008.png %}
其架构主要由三个核心组件构成:
- “规划-执行”双智能体 (Plan-and-Act Dual-Agent):模拟人类的认知与行动分离。
- 分层记忆机制 (Hierarchical Memory):解决长程上下文和个性化问题。
- MCP 工具链 (MCP-based Tooling):标准化的外部能力接入。
2.1 “规划-执行”双智能体架构 (Plan-and-Act Dual-Agent)
为了处理复杂的长程视频任务(例如:“先提取视频中的主角,然后把他放入一个新的背景中,最后配上解说词”),UniVA 采用了双层控制流:
2.1.1 规划智能体 (Planner Agent) —— “大脑”
- 职责:负责高层的意图理解与任务分解。它不直接操作视频,而是生成一个结构化的执行计划 (Execution Plan)。
- 工作流:
- 接收用户的自然语言指令。
- 结合记忆模块中的上下文,分析任务依赖关系。
- 输出一个有向无环图 (DAG) 或线性步骤列表,规定了需要调用哪些工具、参数是什么、以及步骤间的输入输出关系。
- 动态调整:如果后续步骤失败,Planner 可以根据反馈重新规划路径。
2.1.2 执行智能体 (Executor Agent) —— “手脚”
- 职责:负责具体的工具调用与结果验证。
- 工作流:
- 接收 Planner 下发的具体子任务(Sub-task)。
- 通过 MCP 协议 与具体的工具服务器(如 LTX-Video 生成器、Aleph 编辑器)进行通信。
- 监控工具的执行状态,处理简单的运行时错误(如参数格式错误)。
- 将中间结果(如生成的视频路径、提取的 Mask)存入任务级记忆,并反馈给 Planner。
核心洞察:这种分离设计避免了单一 LLM 在处理长序列动作时容易出现的“注意力发散”问题。Planner 专注于逻辑,Executor 专注于细节。
2.2 分层多级记忆 (Hierarchical Multi-level Memory)
视频处理任务通常涉及大量的文件路径、参数配置和用户偏好。UniVA 设计了三层记忆结构来管理这些信息:
-
用户偏好记忆 (User-specific Preference Memory)
- 作用:存储用户的长期习惯(例如:“总是生成 16:9 的视频”、“喜欢赛博朋克风格”)。
- 机制:在会话开始前加载,作为 System Prompt 的一部分注入 Planner,确保个性化体验。
-
任务上下文记忆 (Task Context Memory)
- 作用:维护当前工作流的状态机。
- 内容:存储中间产物(Intermediate Artifacts),如视频片段的文件路径、提取出的关键帧、分割的 Mask ID。
- 重要性:确保多步操作之间的数据流转(Data Flow)不会中断。
-
全球知识库 (Global Knowledge Memory)
- 作用:存储通用的视频处理知识和工具手册。
- 内容:包含各种视频格式的规范、工具的最佳实践(如“LTX-Video 擅长生成什么类型的画面”)。
2.3 基于 MCP 的标准化工具链 (MCP-based Tooling)
为了解决视频工具接口不统一的问题,UniVA 采用了 Model Context Protocol (MCP) 标准。
- 工具服务器化 (Tool as a Server):
- 每一个视频能力(生成、编辑、分割、理解)都被封装为一个独立的 MCP Server。
- 例如,
Generation Server可能后端挂载了 Sora 或 Wan 模型;Editing Server挂载了 Runway Aleph。
- 即插即用 (Plug-and-Play):
- 由于遵循统一的 MCP 接口协议,添加一个新的 SOTA 模型只需要编写一个轻量级的适配器(Adapter),而不需要修改 Agent 的核心代码。
- 支持的能力:
- Analysis: 视频描述、对象检测。
- Generation: Text-to-Video, Image-to-Video.
- Editing: 视频修复 (Inpainting)、风格迁移。
- Tracking: 对象追踪与分割 (SAM2)。
3 评估与基准
由于缺乏能够同时涵盖理解、生成、编辑等综合能力的测试集,作者构建了 UniBench 并进行了全面的对比实验。
3.1 UniBench:全能视频能力基准
为了评估 Agent 在处理复杂、长程视频任务上的能力,作者提出了 UniBench。
-
规模与构成:包含 745 个精心设计的查询(Queries),分为 5 个核心维度:
- 理解 (Understanding): 视频描述、问答。
- 生成 (Generation): 文生视频 (T2V)、图生视频 (I2V)。
- 编辑 (Editing): 风格迁移、对象替换、背景修改。
- 分割 (Segmentation): 视频对象分割 (VOS)。
- 组合任务 (Compositional): 这是核心难点,要求模型在单次会话中串联上述多种能力(例如:“先分割出这辆车,然后把背景换成雪地,最后生成一段它行驶的视频”)。
-
评估方法 (Evaluation Protocol):
- MLLM-as-a-Judge:考虑到视频生成的质量难以通过传统指标(如 PSNR)衡量,作者使用 GPT-4o 作为裁判,对模型输出进行打分(1-5分)或成对比较(Pairwise Comparison)。
- 人工评估 (Human Evaluation):对部分结果进行人工盲测,以校准自动评估的可靠性。
3.2 实验结果分析
实验对比了 UniVA 与当前最先进的闭源多模态大模型(GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro)以及开源模型(InternVL2)。
(% asset_img 20251223100158.png %}
3.2.1 综合能力对比 (Overall Performance)
核心结论:UniVA 在大多数任务上显著优于现有的专有模型,特别是在需要执行力的任务上。
- 组合任务 (Compositional Tasks):
- UniVA 展现出压倒性优势。原因在于它能通过 Planner 将复杂指令拆解,并调用 Executor 实际执行编辑或分割工具。
- 相比之下,GPT-4o 等模型虽然能理解指令,但缺乏直接操作视频像素的“手”,往往只能给出文字建议或拒绝回答。
- 编辑与分割 (Editing & Segmentation):
- UniVA 得益于接入了 SOTA 的专家模型(如 SAM2, Runway Aleph),在任务完成度上远超通用的端到端模型。
3.2.2 细分任务表现
- 视频理解:UniVA 表现具有竞争力,但与顶尖的 GPT-4o 差距不大。这说明在纯感知任务上,原生多模态大模型依然很强。
- 视频生成:通过调用 LTX-Video 等工具,UniVA 生成的视频在物理一致性和指令遵循上优于部分闭源模型的原生生成能力。
3.2.3 消融实验 (Ablation Study)
作者进一步分析了架构中各组件的贡献:
- 记忆模块 (Memory):移除记忆模块后,多轮对话的连贯性大幅下降,证明了 Global/Task/User 三层记忆在维持上下文中的必要性。
- 规划器 (Planner):如果移除 Planner 直接让 LLM 调用工具,复杂任务的成功率明显降低,验证了“思考”与“行动”解耦的重要性。
总结:UniVA 的胜利不是单一模型的胜利,而是系统工程的胜利。它证明了通过 Agent 架构整合现有的 SOTA 专家模型,可以在应用层面上超越参数量更大的端到端模型。
思考
UniVA 是一篇典型的System for AI(而非单纯的 AI Model)论文。它没有提出一种新的视频生成算法,而是通过精妙的架构设计,将现有的 SOTA 能力组装成了一个可用的产品级方案。
核心亮点
- 架构的胜利:证明了在当前阶段,通过 Agentic Workflow(特别是 Planning + Tool Use)来弥补单一模型能力的不足是一条可行且高效的路径。它让 LLM 充当胶水,粘合了视觉领域的碎片化工具。
- 工程化价值:MCP (Model Context Protocol) 的引入非常有远见。视频工具迭代极快(今天 SOTA 是 LTX,明天可能就是 Sora),标准化的接口设计使得 UniVA 具有极强的生命力和扩展性,不会因为某个底层模型的过时而被淘汰。
- 填补空白:UniBench 为复杂的视频 Agent 任务提供了一个急需的评估标准,指出了当前闭源顶流(如 GPT-4o)在“执行侧”的短板。
局限与挑战
- 依赖性风险:UniVA 的上限受限于其调用的底层工具(Tool Models)。如果底层生成模型(如 LTX-Video)本身对物理规律理解偏差,Agent 规划得再好也无法生成完美的视频。
- 推理成本与延迟:双智能体架构 + 多轮工具调用意味着巨大的 Token 消耗和较长的端到端延迟。对于实时性要求高的视频应用,这种“慢思考”模式可能需要优化。
- 多模态对齐:虽然 MCP 统一了接口,但不同工具对 Prompt 的理解能力差异很大(有的需要详细描述,有的只需关键词),Executor 在进行“参数翻译”时仍面临挑战。
一句话评价:UniVA 是迈向 Video AGI 的重要一步,它通过开源和标准化,率先定义了“视频操作系统”的雏形。
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist