VISTA: A Test-Time Self-Improving Video Generation Agent
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | VISTA: A Test-Time Self-Improving Video Generation Agent |
| 作者 | Do Xuan Long, Xingchen Wan, Hootan Nakhost, Chen-Yu Lee, Tomas Pfister, Sercan Ö. Arık |
| 机构 | Google, National University of Singapore |
| 会议 | 2025 arXiv: 2510.15831v1 |
| 总结 | 通过多智能体协作在测试时通过“生成-评估-批判-重写”的迭代循环自主优化提示词,从而提升视频生成质量 |
摘要
尽管文本到视频(T2V)合成技术进展迅速,但生成的视频质量仍然严重依赖于用户提示词的精确度。现有的测试时优化(Test-time optimization)方法虽然在其他领域取得了成功,但在面对视频生成的多面性(Multi-faceted nature)时却显得力不从心。
为了解决这一问题,本文推出了 VISTA,这是一个新颖的多智能体系统,能够在测试时通过迭代循环自主改进视频生成质量。VISTA 的工作流程如下:首先将用户的想法分解为结构化的时间计划;在生成后,通过稳健的成对锦标赛(Pairwise tournament)机制识别出最佳视频;接着,这个获胜的视频会被三个专注于视觉、音频和上下文保真度的专门智能体进行批判;最后,推理智能体综合这些反馈,自省地重写并增强提示词,用于下一轮生成。在单场景和多场景视频生成的实验中,VISTA 始终能提升视频质量以及与用户意图的对齐度,在与最先进基线的对抗中实现了高达 60% 的胜率。人类评估者也表示赞同,在 66.4% 的比较中更偏向 VISTA 的输出。
内容
1 引言 & 背景 & 相关工作
尽管文本到视频(Text-to-Video, T2V)模型(如 Sora, Veo, Kling)取得了显著进展,但生成高质量视频仍然极度依赖于提示工程(Prompt Engineering)。用户往往需要经过多次试错,才能找到生成理想视频的“魔法咒语”。
1.1 现有挑战
现有的优化方法主要集中在训练阶段(如 RLHF),或者是针对大语言模型(LLM)的测试时优化(Test-Time Optimization, 如 ReFT, DSPy)。然而,直接将这些方法迁移到视频生成领域面临三大难题:
- 评估困难:视频包含视觉、音频、时间连贯性等多个维度,很难用单一的奖励模型(Reward Model)给出准确的绝对评分。
- 多模态复杂性:视频生成不仅涉及画面质量,还涉及动作流畅度、物理规律、光影一致性以及音画同步。
- 反馈稀疏:简单的“好/坏”反馈不足以指导模型修正复杂的视觉错误(如“手部畸形”或“物体瞬移”)。
1.2 VISTA 的核心思路
本文提出了 VISTA(Video Self-improving Test-time Agent),这是一个多智能体系统。
作者的核心假设是:与其训练一个完美的生成模型,不如构建一个能够“自我反思”和“自我修正”的智能体系统,在推理阶段(Test-Time)通过迭代优化提示词来提升生成质量。
这类似于人类导演的工作流程:构思脚本 -> 拍摄样片 -> 审片挑刺 -> 修改指令 -> 重拍。
2 VISTA 框架详解
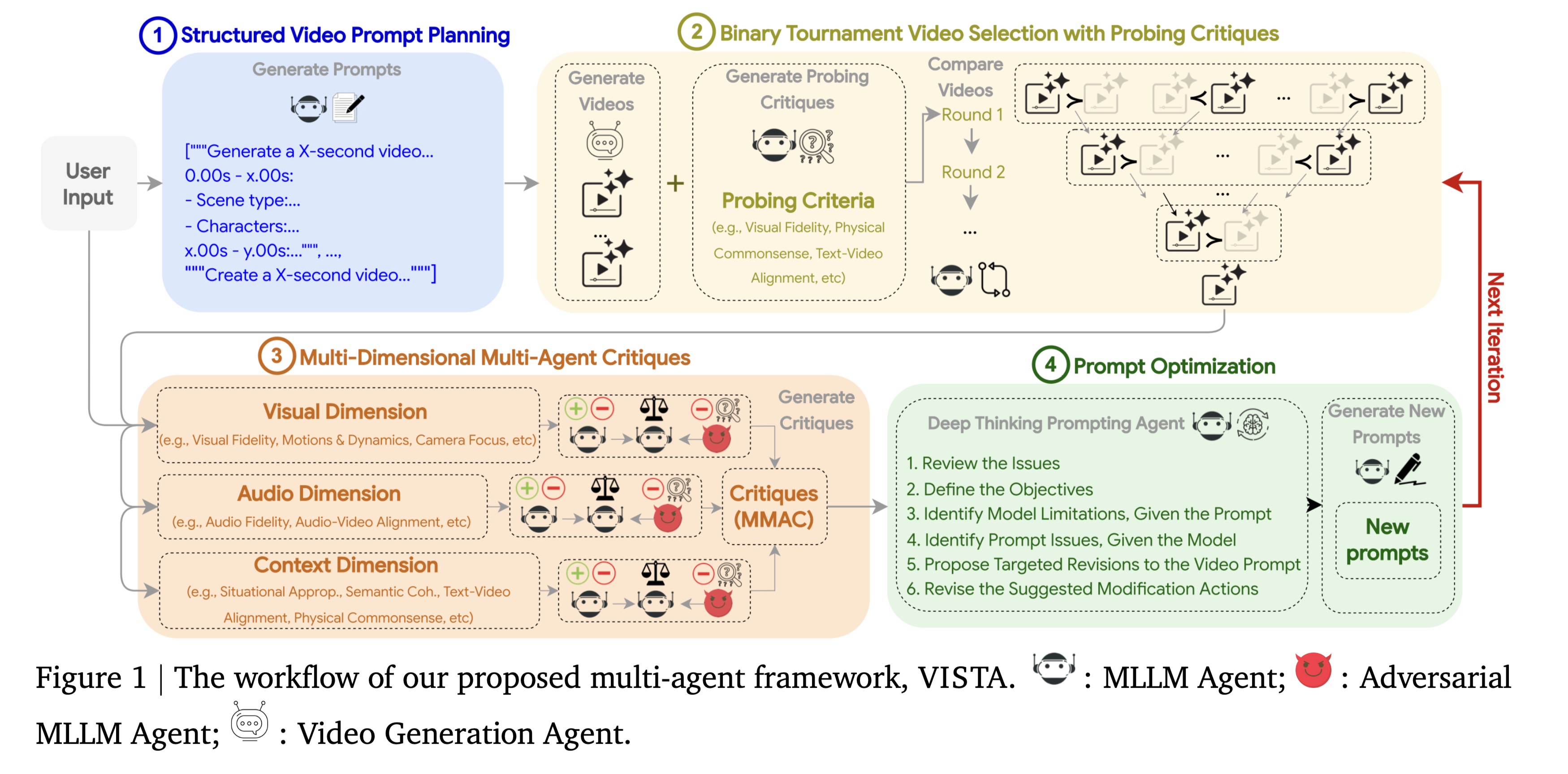
VISTA 采用了一个闭环的迭代优化过程,由五个核心组件(智能体)协同工作。
2.1 规划与分解
- 输入:用户的原始简短提示(User Intent)。
- 动作:Planner Agent 将其分解为结构化的时间计划(Temporal Plan)。
- 目的:对于长视频或复杂场景,单一的文本提示往往会导致模型遗忘后续指令。结构化计划明确了每个时间段(Timestamp)的:
- 场景描述(视觉环境、角色)。
- 动作指令(发生了什么)。
- 运镜方式(Camera movement)。
- 音频提示(背景音、对白)。
2.2 生成与锦标赛选择
- 生成:基于当前的提示词,调用基础 T2V 模型(如 Veo, Imagen Video)生成 $K$ 个候选视频。
- 评估难题:直接给视频打分(1-10分)非常不稳定,VLM(视觉大语言模型)往往难以给出一致的绝对分数。
- 解决方案:采用**成对锦标赛(Pairwise Tournament)**机制。
- 让 VLM(作为裁判)同时观看两个视频(Side-by-side),只判断“哪一个更好”。
- 通过多轮两两PK,选出当前的“最佳视频”(Winning Candidate)。
这种相对评估(Relative Evaluation)比绝对评估要稳健得多,能够有效过滤掉明显的次品。
2.3 多视角批判
选出最佳视频后,系统并不会止步,而是进入“审片”环节。VISTA 部署了三个专门的 Critic Agents,分别关注不同维度:
- Visual Critic:关注图像质量、光照、物理合理性、甚至反射细节(如墨镜里的倒影)。
- Audio Critic:关注音质、音画同步(Lip-sync)、环境音的沉浸感。
- Context Critic:关注上下文一致性,确保视频忠实于用户的原始意图,且多场景之间逻辑连贯。
每个 Critic 都会输出具体的文本反馈(Feedback),指出视频的具体缺陷。
2.4 推理与修正
这是闭环的最后一步,也是 VISTA “智能”的体现。
- Reasoning Agent 汇总所有 Critic 的反馈。
- 它进行自省(Introspection):思考“为什么模型会犯这个错误?”以及“如何修改提示词来纠正它?”。
- 输出:重写后的、增强版的提示词(Refined Prompt),用于下一轮的生成。
3 实验评估
3.1 实验设置
- 基座模型:Google 的 Veo 和 Imagen 3。
- 评估基准:
- Direct Prompting (DP):直接使用用户提示。
- Self-Refine:一种通用的 LLM 自我修正方法。
- Ada-LE:基于进化的提示优化方法。
- 任务场景:
- 单场景生成:侧重细节和物理规律。
- 多场景生成:侧重长视频的叙事连贯性和转场。
3.2 实验结果
-
胜率分析:
- 在与 Direct Prompting 的对比中,VISTA 取得了 60% 以上的胜率(由人类评估)。
- 随着迭代轮数(Round)的增加(从 Round 0 到 Round 2),视频质量呈现单调上升趋势。
-
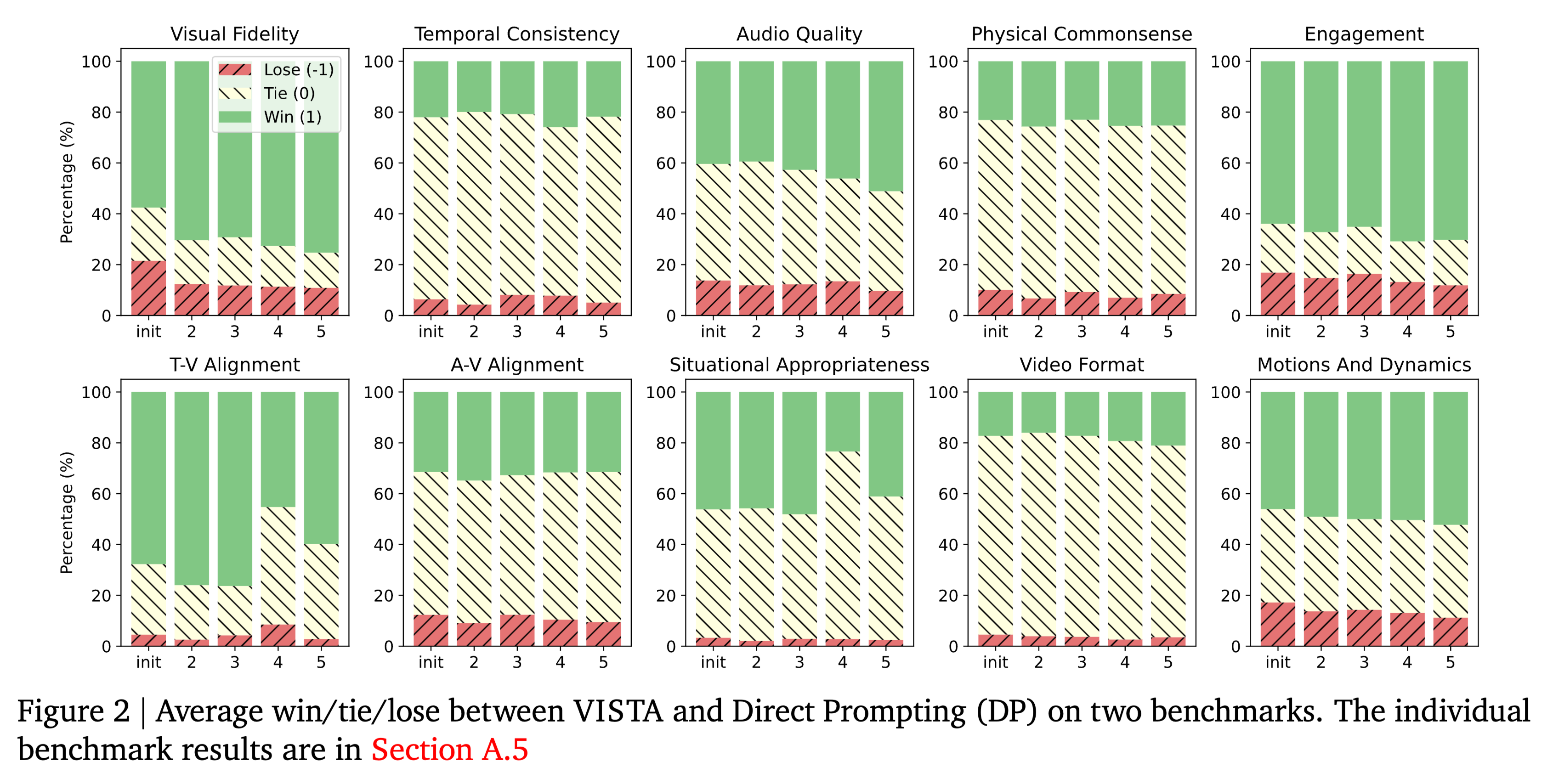
-
不同维度的改进:
- 视觉保真度:VISTA 能够修正模糊的面部、错误的光影。
- 指令遵循:对于复杂的动作描述(如“从A移动到B”),VISTA 的修正提示能显著提高成功率。
3.3 消融实验
- Critic 的重要性:如果移除 Multi-View Critique,仅保留单一的一般性反馈,性能下降显著。说明视频生成需要“专才”来挑刺。
- Tournament 的必要性:如果用绝对评分替代成对PK,选择出的“最佳视频”往往不够好,误导了后续的优化方向。
思考
- 测试时计算(Test-Time Compute)的胜利:VISTA 证明了,不重新训练庞大的视频生成模型,仅通过消耗更多的推理时间(生成多个样本、多轮迭代、多智能体通信),就能显著提升最终产出的质量。这是一个典型的 “Trade inference time for quality” 的案例。
- 与 StoryAgent 的对比:
- StoryAgent 侧重于一致性保持(通过重绘、LoRA微调等硬约束),适合固定角色的连续剧。
- VISTA 侧重于提示词优化(通过自然语言反馈闭环),适合提升单次生成的物理正确性和指令遵循度。
- 两者结合可能是未来的方向:用 VISTA 的框架来优化 StoryAgent 的分镜描述,再用 StoryAgent 的技术来生成。
- 局限性:多轮迭代意味着生成一个视频的成本和时间翻倍。如何减少迭代次数是未来优化的关键。
VISTA: A Test-Time Self-Improving Video Generation Agent