VideoAgent: Self-Improving Video Generation for Embodied Planning
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | VideoAgent: Self-Improving Video Generation for Embodied Planning |
| 作者 | Achint Soni, Sreyas Venkataraman, Abhranil Chandra, Sebastian Fischmeister, Percy Liang, Bo Dai, Sherry Yang |
| 机构 | University of Waterloo, IIT Kharagpur, Stanford University, Georgia Tech, Google DeepMind, NYU |
| 来源 | 2025 arXiv: 2410.10076v3 |
| 总结 | 提出通过“自我调节一致性”机制,结合 VLM 反馈与在线环境交互,迭代优化视频生成策略以用于机器人规划 |
摘要
视频生成已被用于生成控制机器人系统的视觉计划(Visual Plans)。通常的做法是给定图像观测和语言指令,生成视频计划,然后将其转换为机器人控制指令并执行。然而,利用视频生成进行控制的一个主要瓶颈在于生成视频的质量,这些视频往往存在内容幻觉(Hallucinatory content)和不切实际的物理现象,导致从中提取控制动作时任务成功率低下。 虽然扩大数据集和模型规模是一个部分解决方案,但整合外部反馈对于将视频生成落地到物理世界既自然又至关重要。基于这一观察,我们提出了 VideoAgent,用于基于外部反馈自我改进生成的视频计划。VideoAgent 并不直接执行生成的视频计划,而是首先利用一种称为 自我调节一致性(Self-Conditioning Consistency) 的新颖程序来优化生成的视频计划,从而将推理时的计算量(Inference-time compute)转化为更好的生成质量。随着优化后的视频计划被执行,VideoAgent 还能从环境中收集额外数据,以进一步改进视频生成。在 MetaWorld 和 iTHOR 的模拟机器人操作实验中,VideoAgent 大幅减少了幻觉,从而提高了下游操作任务的成功率。我们进一步展示了 VideoAgent 可以有效优化真实机器人的视频,提供了机器人可以作为将视频生成落地物理世界的有效工具的早期证据。
内容
1 引言 & 背景 & 相关工作
尽管文本到视频(Text-to-Video, T2V)模型在生成创意内容方面表现出色,但在作为机器人的**具身规划(Embodied Planning)**工具时,面临着严峻的可靠性挑战。
1.1 核心问题:幻觉与物理违背
- 现状:现有的“视频即策略”(Video as Policy)方法(如 UniPi, AVDC)直接将 T2V 生成的视频转化为机器人动作。
- 痛点:生成的视频经常出现幻觉(Hallucinations)(例如:物体凭空消失、手穿过桌子)或违反物理规律。这导致下游的逆动力学模型(Inverse Dynamics)无法提取出有效的控制指令,任务成功率低。
- 局限性:单纯扩大模型规模(Scaling)在视频领域不仅成本高昂,且难以解决物理一致性问题;同时,视频缺乏类似 LLM 的高质量“思维链”数据。
1.2 VideoAgent 的核心洞察
作者认为,与其强求模型“一次生成完美视频”,不如赋予模型在 推理阶段(Inference-time) 进行自我修正的能力。
这类似于 LLM 中的 “System 2” 思维,即通过花费更多的推理计算量(Inference-time compute)来换取更高的生成质量。
VideoAgent 引入了三个层面的反馈循环:
- 内部循环:通过 Self-Conditioning Consistency 在扩散过程内部进行迭代修正。
- 推理循环:利用 VLM (Vision-Language Model) 作为外部裁判,决定是否需要重绘。
- 训练循环:利用**在线交互(Online Interaction)**的成功轨迹微调模型。
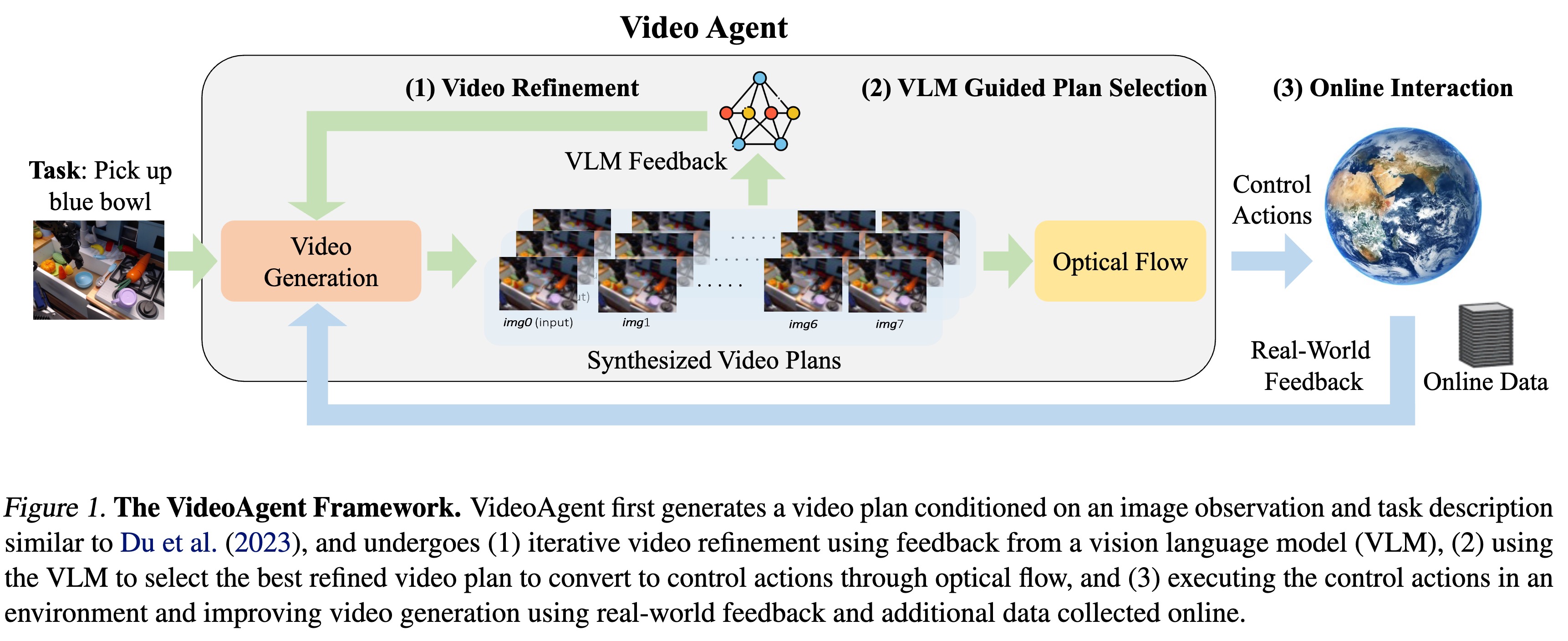
2 核心方法:VideoAgent 框架
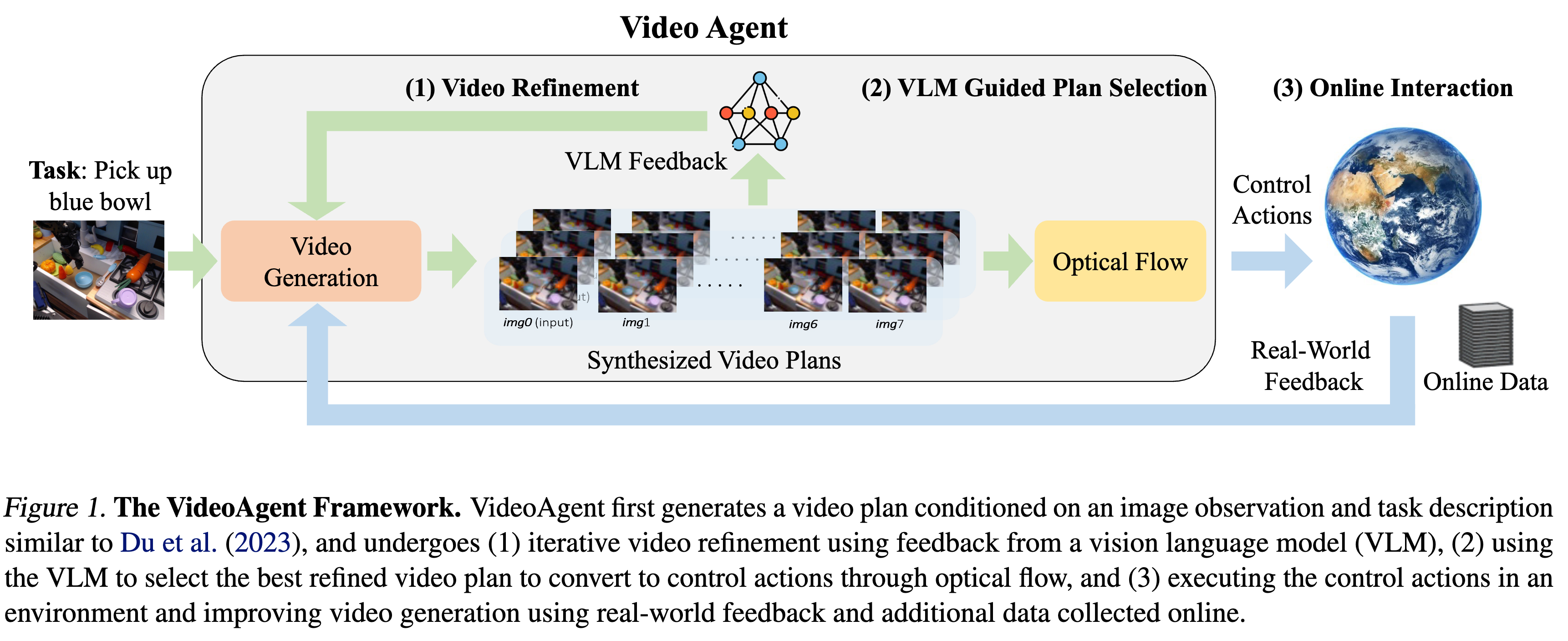
VideoAgent 的核心在于将视频生成看作一个可优化的迭代过程,而非单次前向传递。
2.1 理论基础:自我调节一致性
这是本文在算法层面最大的创新。作者从 一致性模型(Consistency Models) 和 ODE 求解器 的角度重新构建了视频细化(Refinement)过程。
2.1.1 扩散模型的 ODE 视角
扩散模型的去噪过程可以看作是在求解一个常微分方程(ODE):
$$\frac{dx^{(t)}}{dt} = -t \cdot s(x^{(t)}, t)$$
其中 $s(\cdot)$ 是分数函数(Score function)。理想情况下,沿着这条轨迹积分应该能从噪声 $x^{(T)}$ 映射到数据 $x^{(0)}$。
2.1.2传统方法的局限
标准的 DDIM 采样或一致性模型(Consistency Models)通常利用当前的估计值来预测下一步。
- 问题:如果初始生成的视频 $x_{init}$ 已经包含了严重的结构性错误(如物体丢失),标准的去噪过程往往会陷入局部最优,难以“无中生有”地修复它。
2.1.3 Self-Conditioning 机制
VideoAgent 提出在去噪步骤中显式地以“上一次生成的完整视频”作为条件。
定义细化模型(Refinement Model) $\hat{f}{\theta}$,其输入不仅包含当前的噪声 $x^{(t)}$,还包含上一步生成的完整视频 $\hat{x}i$:
$$\hat{x}{i+1} = \hat{f}{\theta}(\hat{x}_i, x^{(t)}, t)$$
这意味着模型可以“看着”之前的错误视频 $\hat{x}i$,并结合当前的噪声 $x^{(t)}$ 来生成一个更好的 $\hat{x}{i+1}$。
2.1.4 损失函数
为了训练这个细化模型,作者设计了一个组合损失函数,包含两部分:
- 扩散损失 (Diffusion Loss):标准的去噪能力,但额外 conditioned on $\hat{x}$。
- 一致性损失 (Consistency Loss):强制模型在不同的细化迭代中保持一致性(即 $f(\hat{x}_1) \approx f(\hat{x}_2)$),促进收敛。
总损失函数 $\mathcal{L}(\theta)$ 定义为:
$$\mathcal{L}(\theta) = \mathcal{L}{video-diffusion} + \lambda \cdot \mathcal{L}{SC-consistency}$$
其中 $\mathcal{L}{SC-consistency}$ 具体形式为:
$$\mathcal{L}{SC} = \underbrace{\mathbb{E}[||\hat{f}{\theta}(\hat{x}, x^{(t)}, t) - x^{(0)}||^2]}{\text{Self-Conditioned Denoising}} + \mu \underbrace{\mathbb{E}[||\hat{f}_{\theta}(\hat{x}1, x^{(t)}, t) - \hat{f}{\theta}(\hat{x}2, x^{(t)}, t)||^2]}{\text{Inter-iteration Consistency}}$$
个人理解:第二项(一致性正则化)非常关键。它防止模型在迭代细化时“反复横跳”,强制模型即使输入了不同的历史版本 $\hat{x}_1, \hat{x}_2$,也应该指向同一个正确的真值 $x^{(0)}$。
2.2 推理流程:VLM 引导的生成
在推理阶段,VideoAgent 不会无休止地细化,而是引入了一个停止机制。
- VLM 裁判:使用 GPT-4 Turbo 作为奖励模型 $\hat{\mathcal{R}}$。
- Prompt 设计:不仅让 VLM 判断 Pass/Fail,还可以提供描述性反馈 (Descriptive Feedback)(如:“锤子没有对准钉子”)。
- 反馈注入:如果 VLM 提供了文本反馈,这个文本也会作为 Condition 输入到细化模型中(见 Eq 10)。
- 停止条件:
$$x_{refined} = \hat{x}_{i^} \quad \text{where } i^ = \min {i : \hat{\mathcal{R}}(\hat{x}_i) = 1}$$
2.3 在线自我改进 (Online Self-Improvement)
VideoAgent 能够像强化学习 Agent 一样在部署中学习。
- 执行与过滤:将生成的 $x_{refined}$ 通过光流(Optical Flow)转换为动作执行。如果环境反馈任务成功(Reward=1),则保留该轨迹。
- 数据集聚合:$\mathcal{D}{new} = \mathcal{D} \cup { (\hat{x}{refined}, g) | \text{Success} }$。
- 微调 (Finetuning):使用新数据继续优化 $\hat{f}_{\theta}$。这使得模型能逐渐“记住”那些经过艰难推理才得到的正确轨迹(Amortized Inference)。
3. 实验评估
3.1 实验设置
- 环境:Meta-World (11个机械臂任务), iTHOR (导航), BridgeData V2 (真实世界数据)。
- 基线 (Baselines):AVDC (Action from Video Dense Correspondence), UniPi, Diffusion Policy。
- 模型参数:基于 U-Net 的视频扩散模型,32 head channels, 100 timesteps。
3.2 核心结果
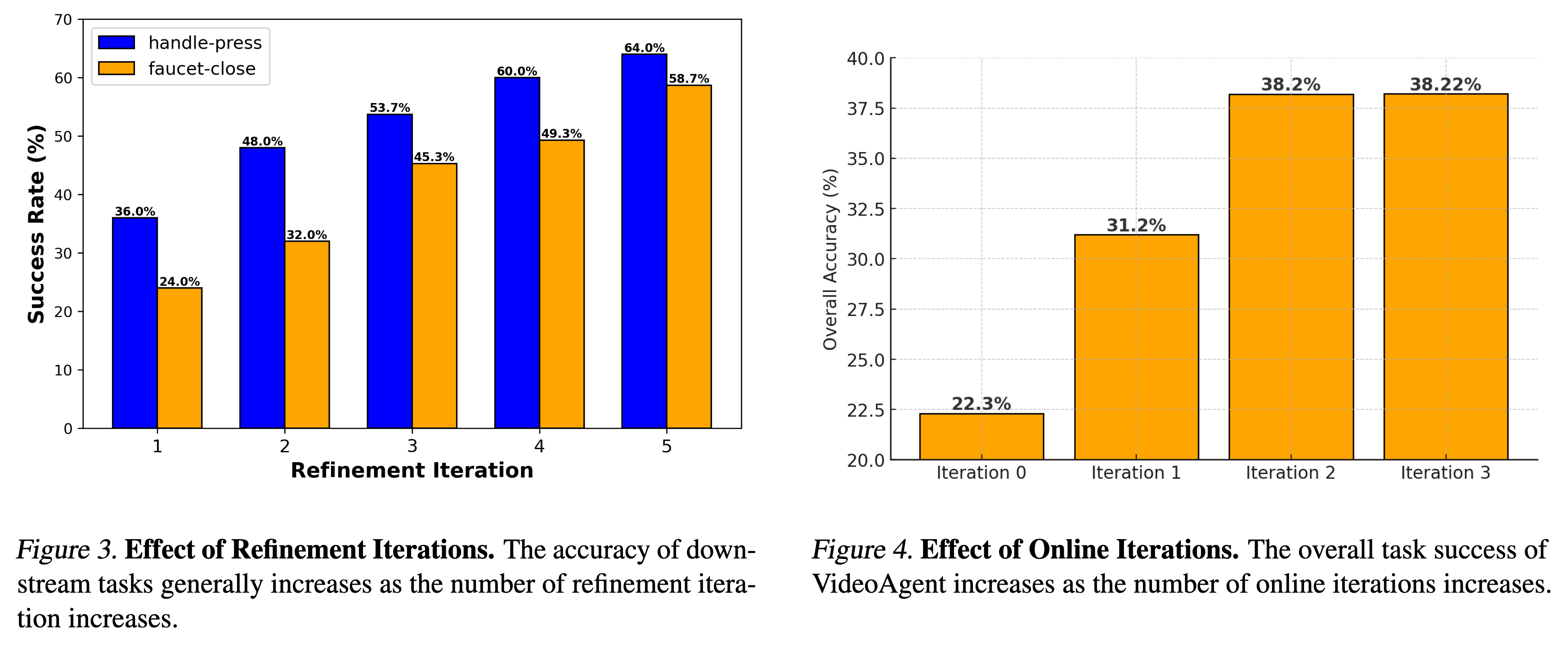
- Meta-World 成功率:
- Zero-shot:VideoAgent (22.3%) 优于 AVDC (19.6%)。
- With Online Learning:迭代两轮后提升至 38.2%,结合 Replan 机制可达 53.7%。
- 下图显示了 Inference-time compute 的价值。
-
- iTHOR 导航:
- VideoAgent 在所有房间类型(厨房、客厅等)中均优于 AVDC。
- 真实世界 (BridgeData V2):
- 使用 CLIP Score 和 Flow Consistency 等指标评估。
- VideoAgent 在 Factual Consistency (事实一致性) 上得分显著更高,说明物理违背减少了。
3.3 消融实验 (Ablation Study)
- 反馈类型的影响:
Binary(仅好坏): 23.8%Suggestive(带文本建议): 26.6%- 结论:VLM 提供的具体修改建议(如“把手往左移”)能显著帮助扩散模型修正视频。
- VLM 的准确率:
- 作者发现 GPT-4 Turbo 在判断视频质量时的准确率约为 69% (Unweighted)。
- Trick:通过加权 Prompt (Penalizing false positives),将 Precision 从 0.65 提升到了 0.92。宁可错杀(拒绝好视频),不可放过(接受坏视频)。
思考
- 核心贡献:VideoAgent 是将 System 2 Thinking(慢思考/推理)引入视频生成的一个典范。它证明了在不增加模型参数量的情况下,通过测试时计算(Test-time Compute)和迭代细化,可以解决生成模型“由于概率采样导致的物理不一致”问题。
- 与 VISTA 的对比:
- VISTA (Google, arXiv 2025) 侧重于优化 Prompt(让 LLM 重写提示词)。
- VideoAgent (本文) 侧重于优化 Latents(通过 Self-Conditioning 在像素/潜空间层面修补视频)。
- 两者是互补的:VISTA 修正意图,VideoAgent 修正物理细节。
- 局限性:
- 推理延迟:生成一个视频需 10s,但转化为动作并执行反馈循环需要 25s。这种高延迟使得它目前难以用于实时性要求高的机器人控制。
- 动作提取瓶颈:目前仍依赖 Optical Flow 提取动作,这本身是一个有损过程。如果光流估计错误,即使视频生成对了,动作也可能错。
VideoAgent: Self-Improving Video Generation for Embodied Planning