RAGDoll: Efficient Offloading-based Online RAG System on a Single GPU
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | RAGDoll: Efficient Offloading-based Online RAG System on a Single GPU |
| 作者 | Weiping Yu, Ningyi Liao, Siqiang Luo, Junfeng Liu |
| 机构 | Nanyang Technological University |
| 来源 | 2025 arXiv: 2504.15302v1 |
| 总结 | 针对单张消费级 GPU 的资源受限场景,通过解耦检索与生成流水线、分层内存联合调度及自适应批处理,实现高效的 RAG 在线服务。 |
摘要
检索增强生成(RAG)通过引入相关外部知识提高了大语言模型(LLM)的生成质量。然而,由于内存有限以及模型和知识库规模的不断增加,在消费级平台上部署 RAG 极具挑战性。本文介绍了 RAGDOLL,这是一个专为资源受限平台设计的资源高效型、自适应 RAG 服务系统。RAGDOLL 基于一个核心洞察:RAG 的检索和 LLM 生成阶段具有不同的计算和内存需求,传统的串行工作流会导致大量的空闲时间和资源利用率低下。基于此,RAGDOLL 将检索和生成解耦为 并行流水线(parallel pipelines),并结合 联合内存放置(joint memory placement) 和 动态批处理调度(dynamic batch scheduling) 策略,以优化跨不同硬件设备和工作负载的资源使用。大量实验表明,RAGDOLL 能有效适应各种硬件配置和 LLM 规模,与基于 vLLM 的串行 RAG 系统相比,平均延迟实现了高达3.6 倍的加速。
内容
![[Pasted image 20251223100958.png]]
1 引言 & 背景 (Introduction & Background)
随着大语言模型(LLM)的发展,检索增强生成(RAG)已成为在不重新训练模型的情况下引入外部知识(如企业本地数据)的关键技术。虽然数据中心级的 RAG 服务(如 RAGCache, CacheBlend)已有所研究,但在资源受限的消费级平台(如单张 GPU) 上部署 RAG 仍面临巨大挑战。
1.1 核心挑战:资源受限下的性能瓶颈
在单 GPU 环境下(例如 12-24GB 显存,有限的系统内存),现有的 RAG 服务面临着独特的“计算-存储”冲突。作者通过系统性评估指出了三大挑战:
- C1: 内存密集型操作的严重冲突
RAG 的两个核心组件——向量数据库和LLM——都在争夺有限的内存资源。- 向量数据库:为了处理海量知识库,通常采用基于磁盘的存储(Disk-based),但为了低延迟检索,需要将热点分区(Partitions)加载到 CPU 内存。
- LLM 推理:为了在消费级显卡上运行大模型(如 Llama-3-70B),必须使用卸载技术(Offloading) 将权重和 KV Cache 在 GPU、CPU 和磁盘之间移动。
- 冲突点:如图所示,增加生成阶段的 Batch Size 会显著增加 KV Cache 的内存占用,迫使系统将更多的模型权重或数据库分区挤出内存(Offload 到磁盘),从而引发严重的 I/O 抖动和延迟。
![[Pasted image 20251223101010.png]]
- C2: 串行执行导致的空闲等待
现有的 RAG 框架通常采用简单的串行模式:Query -> Retrieval (CPU intensive) -> Generation (GPU intensive)。- 资源利用率低:检索时 GPU 空闲,生成时 CPU 空闲。
- 延迟累积:如图所示,在串行模式下,检索和生成的等待时间占据了整体延迟的很大一部分(从 80% 高达 90%)。系统无法在检索下一个 Batch 的同时进行当前 Batch 的生成。
![[Pasted image 20251223101020.png]]
- C3: 在线服务的不规则负载
与离线批处理不同,在线服务(On-demand Serving)的请求到达率是波动的。- 静态配置失效:固定的 Batch Size 无法应对高峰期的积压(Backlog)或低谷期的延迟敏感需求。
- 扩缩容差异:检索和生成对 Batch Size 的敏感度不同。检索(CPU 密集)通常能更好地处理大 Batch,而生成(GPU 密集)在显存受限时,大 Batch 会导致严重的计算和 I/O 瓶颈。
1.2 现有解决方案的局限性
目前的优化技术通常只关注 RAG 链路中的某一个环节,难以解决上述的系统性问题(参考中的分类):
| 技术类别 | 代表工作 | 局限性 (Gap) |
|---|---|---|
| LLM 服务系统 | vLLM, FlexGen | 主要关注生成阶段的显存管理(如 PagedAttention)或吞吐量,未考虑 RAG 检索阶段带来的内存竞争和 CPU 负载。 |
| 向量数据库 | Milvus, FAISS | 专注于检索吞吐,不感知 LLM 的生成状态,无法配合进行端到端的资源调度。 |
| 高性能 RAG 系统 | RAGCache, PipeRAG | 通常假设拥有充足的硬件资源(多卡 H800/A100),其策略在单卡资源受限环境下容易导致内存溢出(OOM)或性能急剧下降。 |
1.3 本文动机
基于上述分析,作者认为 RAG 的检索和生成在计算设备(CPU vs GPU)和内存模式上具有天然的正交性(Orthogonality)。
因此,本文的核心动机是设计一个自适应系统(RAGDoll),通过以下方式打破资源瓶颈:
- 解耦流水线:将检索和生成拆分为并行工作的流水线,掩盖设备空闲时间。
- 分层内存联合调度:统一管理 GPU 显存、CPU 内存和磁盘空间,动态平衡 DB 分区和 LLM 张量的驻留位置。
- 负载感知调度:根据实时积压情况(Backlog)动态调整 Batch Size,而非使用静态配置。
2 动机
2.1 问题形式化:资源受限的优化难题
作者将资源受限的 RAG 服务建模为一个约束优化问题。目标是在满足各级存储设备(GPU 显存 $D_{gpu}$、CPU 内存 $D_{cpu}$、磁盘 $D_{disk}$)容量限制的前提下,最小化期望延迟 $\mathcal{L}$。
$$
\min \mathcal{L}(B, \theta, \lambda(t)) \
\text{s.t. } \mathcal{P}_{\theta}(V, M, C) + W(B, M) \le D
$$
其中:
- $B$:生成阶段的 Batch Size。
- $\theta$:内存放置策略(Memory Placement Strategy)。
- $\lambda(t)$:随时间变化的请求到达率。
- $\mathcal{P}_{\theta}$:向量数据库 $V$、LLM 模型 $M$ 和运行缓存 $C$ 在各设备上的内存占用。
- $W(B, M)$:执行时所需的额外工作空间(如 KV Cache),它与 Batch Size $B$ 强相关。
2.2 现有系统的三大痛点
通过对现有系统(如 vLLM, FlexGen 配合 Milvus)在单卡环境下的实测分析,作者揭示了三个关键观察(Insights):
-
内存资源争夺
- 现象:图中展示了不同配置下的延迟分布。
- 分析:为了降低检索延迟,需要将更多向量数据库分片(Partitions)缓存在 RAM 中;为了降低生成延迟,需要将更多 LLM 权重留在 GPU 中。然而,当 Batch Size 增大($B=128$)时,KV Cache 的显存占用激增,迫使系统将模型权重和 DB 分片挤出内存(Offload 到磁盘),导致性能急剧下降。这表明各组件间存在激烈的资源竞争。
-
串行执行的等待时间
- 现象:CPU(检索)和 GPU(生成)的利用率在时间轴上是交替的。
- 分析:在处理 Batch 1 时,系统完全在等待;直到 Batch 1 检索完成,GPU 才开始工作。这种串行模式导致了大量的设备空闲。作者指出,外部延迟(积压等待) 和内部延迟(设备利用率低) 共同构成了主要的延迟来源。
-
不规则负载下的调度失效
- 现象:在线服务的请求到达率波动剧烈。
- 分析:检索(CPU 密集)和生成(GPU 密集)对 Batch Size 的扩展性表现不同。检索时间随 Batch 增大变化较小,而生成时间(在显存受限需 Offloading 时)随 Batch 增大显著增加。传统的统一 Batch 策略(如 vLLM 的细粒度调度)在内存受限场景下,面对大量积压请求时反而可能因频繁上下文切换降低性能。
3 RAGDoll
3.1 总体架构
RAGDoll 的核心思想是解耦与联合。如图所示,系统主要包含三个模块:
- 联合流水线:利用分层内存放置统一管理 GPU/CPU/Disk 资源。
- 多流水线计算:将检索和生成拆分为独立的 Workers,实现 CPU 和 GPU 的并行处理。
- 配置中心:包含离线分析器(Offline Profiler)和在线调度器(Online Scheduler),负责动态调整 Batch Size 和内存布局。
![[Pasted image 20251223101030.png]]
3.2 分层内存放置
为了解决内存争夺,RAGDoll 将所有组件的内存使用纳入统一管理,动态在三级存储(GPU VRAM, CPU RAM, Disk)间调度:
-
数据库分片管理 (Database Partitions):
- 不再是静态加载,而是根据当前内存余量,动态地 Load 或 Release 向量库的分片。
- 策略:在检索 Batch 之间执行分片的换入换出。
-
LLM 权重与 KV Cache:
- 采用基于百分比的放置策略(例如:50% 权重在 GPU,50% 在 CPU)。
- 系统会根据计算出的最优配置,在生成 Batch 之间迁移张量。
-
动态计算工作区 (Computation Workspace):
- 根据当前的 Batch Size 预留必要的中间计算内存(Attention Matrices 等),防止 OOM。
Lock 机制:为了保证并发安全,RAGDoll 在检索和生成 Workers 之间设计了精细的锁机制,确保在重新配置内存布局(如卸载权重)时不会发生读写冲突。
3.3 LLM 预取流水线
![[Pasted image 20251223101038.png]]
针对单卡 Offloading 场景,RAGDoll 改进了 FlexGen 的预取机制。
- 对比传统方法: 图中显示,传统方法(FlexGen)通常只预取下一层(Layer $i+1$),容易受 CPU 调度抖动影响导致计算停顿。
- RAGDoll 改进:
- 连续入队 (Continuous Enqueuing):只要内存允许,预取队列会持续加入后续层(Layer $i+2, i+3…$),最大化 I/O 带宽利用率。
- 阶段感知 (Phase-aware):区分 Prefill(预填充) 和 Decoding(解码) 阶段。
- Prefill:激活值(Activation)占用大,预取策略保守。
- Decoding:激活值占用小,预取策略激进(Aggressive),加载更多层以掩盖计算延迟。
3.4 自适应服务配置 (Adaptive Serving Configuration)
系统采用“离线分析 + 在线调整”的两步走策略来应对动态负载。
1. 离线主动分析 (Offline Active Profiling)
- 目标:寻找平衡点,使检索流水线和生成流水线的延迟尽可能匹配,减少短板效应。
- 约束:必须满足硬件内存限制(公式 2 & 3)。
$$w_{gpu} \cdot W_{total} + c_{gpu} \cdot C(B) + H(B) \le M_{gpu}$$ - 简化搜索:作者观察到检索时间主要受加载分片数量影响,对 Batch Size 不敏感。因此,分析器将检索时间视为常量,重点搜索最佳的生成 Batch Size。
2. 在线积压感知调度 (Online Backlog-aware Batch Scheduling)
- 场景:当请求积压(Backlog)时,如何选择处理的 Batch Size?
- 决策逻辑:基于离线分析的数据,实时计算不同划分方式的预期延迟。
- 如果处理时间 $T(n)$ 随 $n$ 呈亚线性增长(Sublinear),则倾向于大 Batch。
- 如果呈超线性增长(例如因内存不足导致频繁 Swap),则切分为小 Batch(如 $k$ 个小 Batch)更优。
- 公式推导证明了在特定增长率下,切分 Batch 能降低平均排队延迟(公式 6-8)。
- 差异化策略:
- 检索 Worker:倾向于大 Batch(CPU 向量计算对 Batch 不敏感)。
- 生成 Worker:根据显存压力动态调整,防止因 Batch 过大触发严重的 Disk Offloading。
4 实现
作者实现了一个约 5000 行代码的原型系统,整合了业界主流框架:
- 基础框架:使用 LangChain 构建 RAG 流程,Milvus 作为向量数据库,FlexGen 作为 LLM 推理(支持 Offloading)的基础组件。
- 懒惰动态传输 (Lazy Dynamic Transfer):
- 由于策略变化是渐进的,系统并不在每次策略更新时同步传输所有张量。
- 利用后台 CUDA 流异步传输权重,仅在计算即将需要该张量时才进行同步。
- 对于已卸载到磁盘的权重,保留文件名以便复用,避免重复写入开销。
- 容错机制 (Fault Tolerance):
- 在离线分析和在线运行阶段都加入了容错设计。
- 检索侧:对中间检索块(Chunks)进行 Checkpoint。
- 生成侧:如果发生 OOM,优先尝试将更多 KV Cache 移至低层级存储;如果失败,再卸载部分模型权重。这种分级降级策略避免了完全重启。
5 实验
4.5.1 实验设置
- 硬件平台:
- PF-High: NVIDIA A30 (24GB VRAM) + 256GB RAM (相对高端)
- PF-Low: NVIDIA A5000 (12GB VRAM) + 176GB RAM (资源严重受限)
- 模型与数据:
- LLM: Llama-3.1-8B 和 Llama-3.1-70B。
- 知识库: TriviaQA (256GB 向量数据)。
- 基线对比 (Baselines):
- AccRAG: 基于 Hugging Face Accelerate 的串行 RAG。
- vLLMRAG: 基于 vLLM 的串行 RAG(代表目前最先进的在线推理系统)。
- 负载:模拟泊松分布的到达率,包含从低负载到过载(Overload)的多个阶段。
4.5.2 核心结果:端到端性能
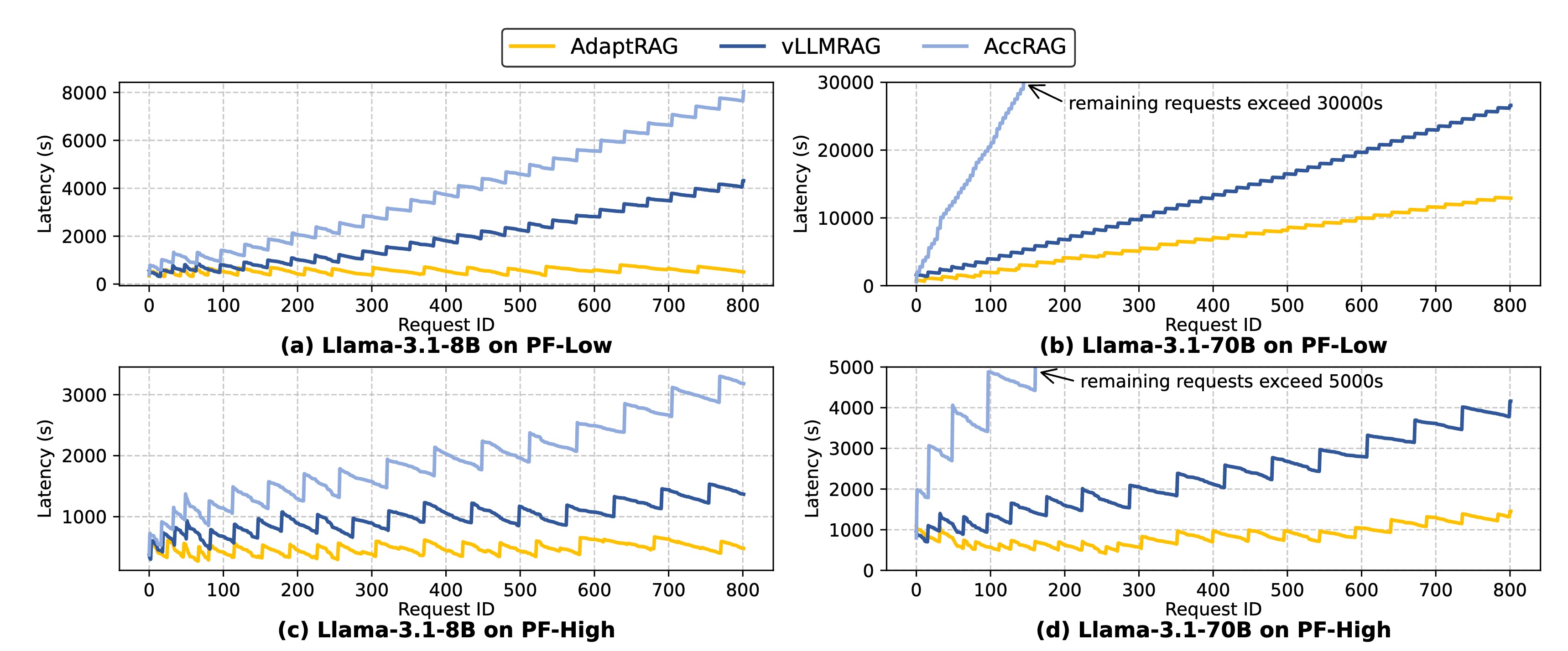
![[Pasted image 20251223101052.png]]
- 总体加速:
- RAGDoll 相比 vLLMRAG 实现了 1.9x - 3.6x 的平均延迟降低。
- 相比 AccRAG,在 70B 大模型上的加速比高达 11.7x。
- 高负载下的稳定性:
- 如图所示,随着请求速率增加,基线系统(vLLMRAG, AccRAG)的延迟呈现指数级增长(积压严重)。
- RAGDoll 的延迟增长相对平缓,且单次请求的最大延迟被控制在合理范围内(例如 8B 模型在 PF-Low 上始终低于 1000s)。
- 延迟拆解 (Breakdown):
- RAGDoll 的主要优势在于极低的等待时间 (Waiting Time)。例如在 PF-Low 跑 8B 模型时,RAGDoll 的等待时间仅为 vLLMRAG 的 10% (170s vs 1640s)。
- 这证明了流水线并行和动态 Batch 策略成功消除了因资源争夺导致的“假死”排队现象。
4.5.3 动态调度分析
- 自适应策略的可视化:
- 下图展示了运行时的参数变化:当工作负载增加时,系统自动增大生成 Batch Size(从 16 到 48)以提升吞吐,同时减少 CPU 上的 KV Cache(40% -> 15%)和减少驻留的 DB 分片(3 -> 2)以腾出内存空间。
- 这种“以空间换时间,以磁盘换内存”的动态权衡是静态策略无法做到的。
![[Pasted image 20251223101101.png]]
4.5.4 消融实验与案例研究
- 消融研究:
- 去流水线 (No Pipeline):性能下降最严重(延迟增加 38%-58%),证明解耦检索和生成是核心收益来源。
- 静态 Batch:去除动态 Batch 策略后,延迟显著增加,说明单一配置无法兼顾低负载和高负载。
- 基于磁盘的索引 (On-Disk Index / DiskANN):
- 当使用 DiskANN 这类硬盘索引时,RAGDoll 依然表现优异,而 vLLMRAG 性能不仅未提升反而略有下降(因索引加载的 I/O 开销)。RAGDoll 能自动感知索引带来的内存节省,从而分配更多内存给 LLM,实现全局最优。
思考
-
边缘侧/消费级 RAG 的破局点:
这篇文章非常精准地切中了当前“个人 RAG”或“端侧 RAG”的痛点。大多数现有的 RAG 优化(如 RAGCache)都默认在数据中心环境(多卡 H100/A100 + TB 级内存)下运行,追求的是极致的 Cache 命中率。而 RAGDoll 关注的是生存问题——如何在单张 12G/24G 显存的卡上,既跑 70B 模型又跑 256GB 的向量库,还不能卡死。它的核心贡献在于证明了:在资源匮乏时,精细化的“计算-存储”联合调度比单纯的模型算法优化更重要。 -
正交性利用 (Orthogonality):
作者敏锐地捕捉到了 Retrieval (CPU-bound, Batch-insensitive) 和 Generation (GPU-bound, Batch-sensitive) 的正交特性。这种异构流水线设计思路不仅适用于 RAG,其实也可以推广到其他涉及“CPU 预处理 + GPU 推理”的复杂 AI 工作流(如视频理解、多模态推理)。 -
复杂度与通用性的权衡:
虽然效果显著,但 RAGDoll 的实现复杂度较高。它深度侵入了推理框架(FlexGen)的内存管理层,且需要对数据库(Milvus)的分片加载进行控制。这种深度耦合(Co-design) 可能会限制其对新模型架构或新数据库的适配速度。如果未来 vLLM 原生支持更激进的 Heterogeneous Offloading,RAGDoll 的部分策略可能会被集成进去。
RAGDoll: Efficient Offloading-based Online RAG System on a Single GPU