UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist |
| 作者 | Zhengyang Liang, Daoan Zhang, Huichi Zhou, Rui Huang, Bobo Li, Yuechen Zhang, Shengqiong Wu, Xiaohan Wang, Jiebo Luo, Lizi Liao, Hao Fei |
| 机构 | Singapore Management University, University of Rochester, University College London, NUS, CUHK, Stanford University |
| 来源 | 2024 arXiv: 2406.04325v |
| 总结 | 提出了一个开源的全能型多智能体框架 UniVA,利用“规划-执行”双智能体架构和基于 MCP 的工具链,统一了视频理解、生成、编辑等任务,解决复杂长程视频工作流问题。 |
摘要
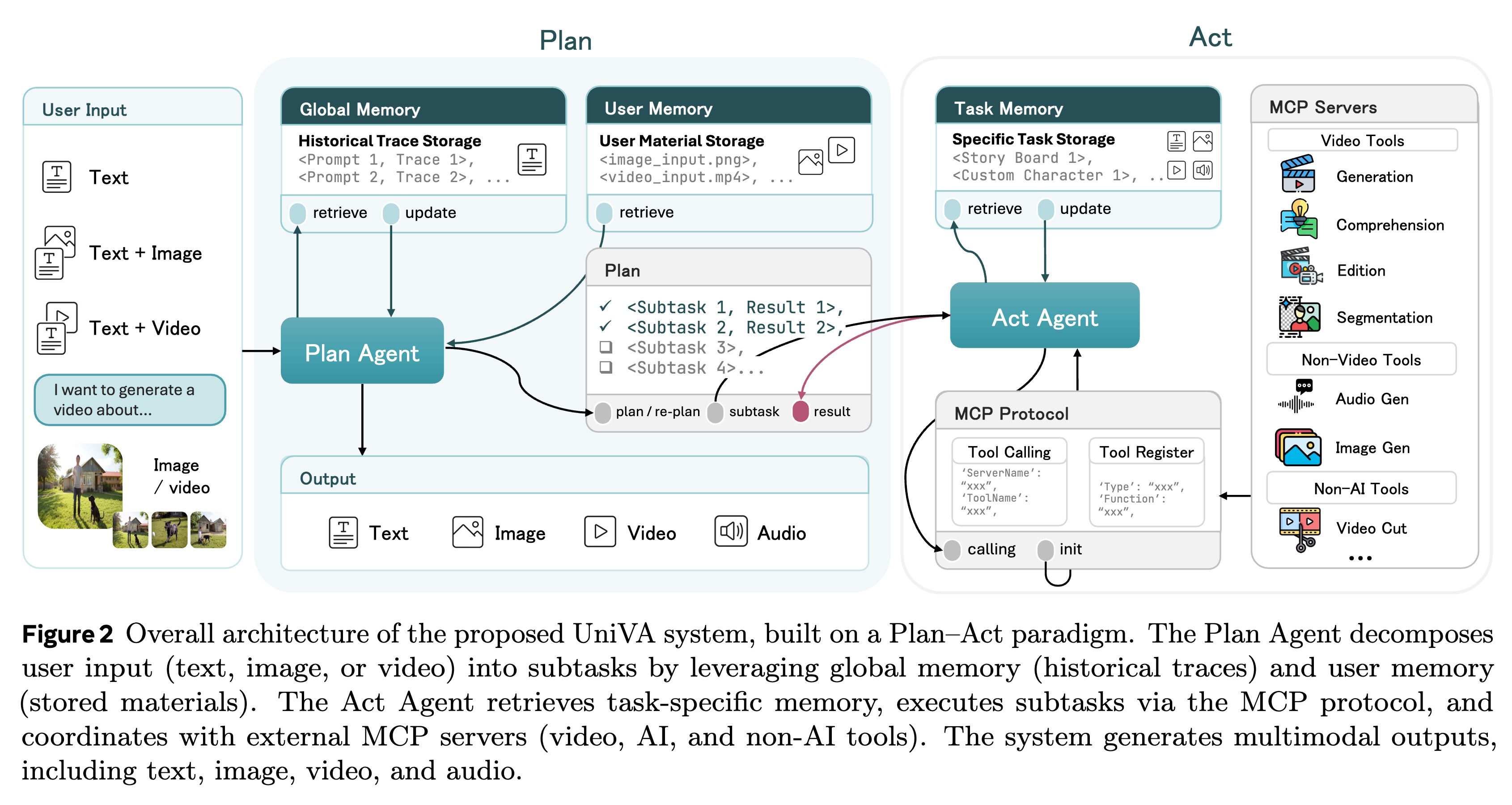
虽然专用的 AI 模型在孤立的视频任务(如生成或理解)上表现出色,但现实世界的应用往往需要结合这些能力的复杂迭代工作流。为了弥补这一差距,我们推出了 UniVA,这是一个面向下一代视频通用工具(Video Generalist)的开源、全能多智能体框架,它将视频理解、分割、编辑和生成统一到了连贯的工作流中。 UniVA 采用 “规划-执行”(Plan-and-Act)双智能体架构 来驱动高度自动化和主动的工作流:
* 规划智能体(Planner Agent):解释用户意图,并将其分解为结构化的视频处理步骤。
* 执行智能体(Executor Agent):通过模块化的、基于 MCP(Model Context Protocol) 的工具服务器(用于分析、生成、编辑、追踪等)来执行这些步骤。
通过分层多级记忆(Hierarchical Multi-level Memory)——包含全球知识、任务上下文和用户特定偏好——UniVA 维持了长程推理能力、上下文连续性以及用户个性化。
为了全面评估 UniVA,我们提出了 UniBench,这是一个包含 745 个复杂多步骤查询的基准测试,涵盖生成、理解、编辑及其组合任务。实验表明,UniVA 在处理复杂视频任务方面显著优于现有的专有模型(如 Claude 3.5 Sonnet 和 GPT-4o),确立了其作为视频领域多功能且强大的开源助手的地位。