VISTA: A Test-Time Self-Improving Video Generation Agent
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | VISTA: A Test-Time Self-Improving Video Generation Agent |
| 作者 | Do Xuan Long, Xingchen Wan, Hootan Nakhost, Chen-Yu Lee, Tomas Pfister, Sercan Ö. Arık |
| 机构 | Google, National University of Singapore |
| 会议 | 2025 arXiv: 2510.15831v1 |
| 总结 | 通过多智能体协作在测试时通过“生成-评估-批判-重写”的迭代循环自主优化提示词,从而提升视频生成质量 |
摘要
尽管文本到视频(T2V)合成技术进展迅速,但生成的视频质量仍然严重依赖于用户提示词的精确度。现有的测试时优化(Test-time optimization)方法虽然在其他领域取得了成功,但在面对视频生成的多面性(Multi-faceted nature)时却显得力不从心。
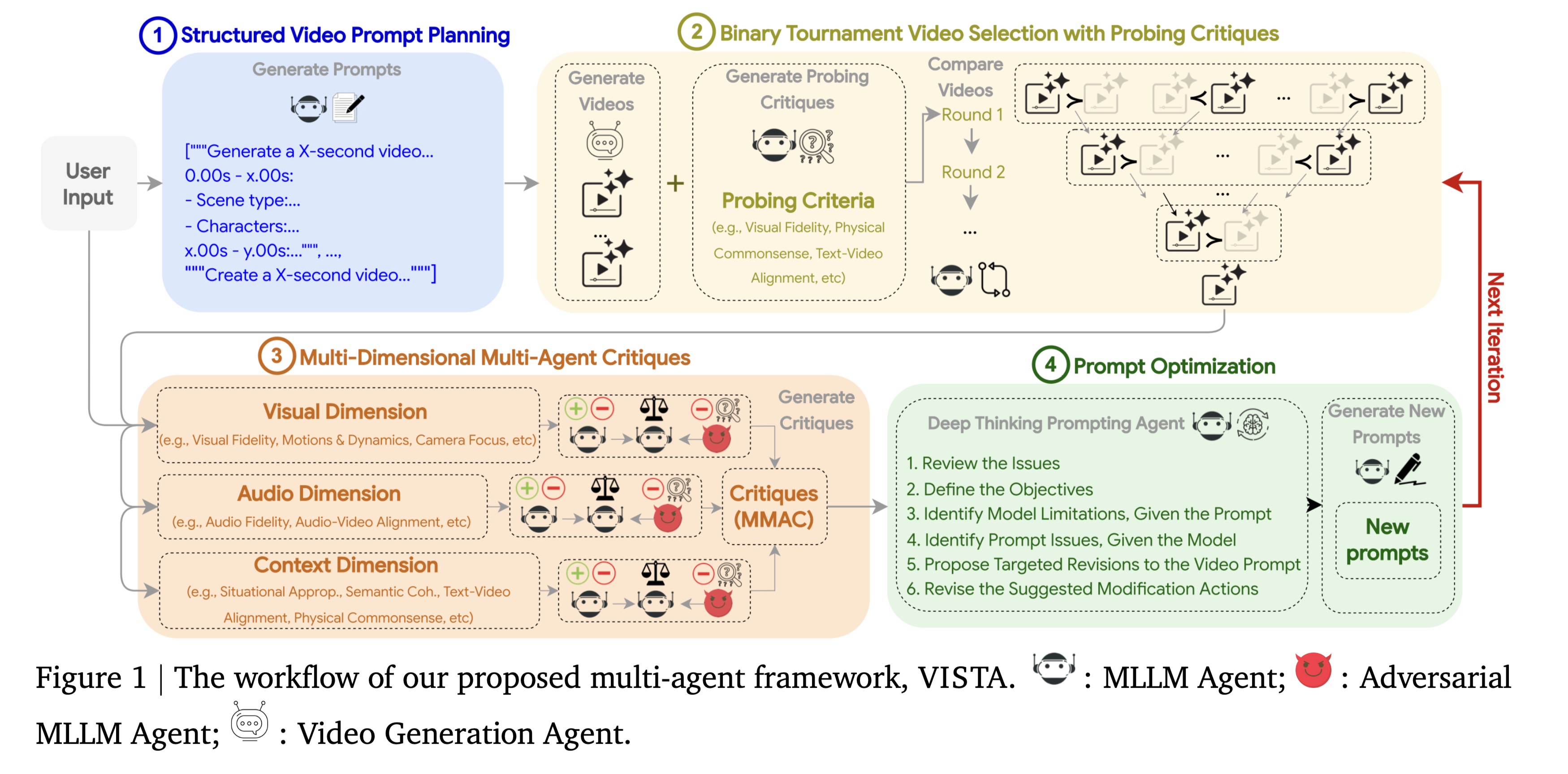
为了解决这一问题,本文推出了 VISTA,这是一个新颖的多智能体系统,能够在测试时通过迭代循环自主改进视频生成质量。VISTA 的工作流程如下:首先将用户的想法分解为结构化的时间计划;在生成后,通过稳健的成对锦标赛(Pairwise tournament)机制识别出最佳视频;接着,这个获胜的视频会被三个专注于视觉、音频和上下文保真度的专门智能体进行批判;最后,推理智能体综合这些反馈,自省地重写并增强提示词,用于下一轮生成。在单场景和多场景视频生成的实验中,VISTA 始终能提升视频质量以及与用户意图的对齐度,在与最先进基线的对抗中实现了高达 60% 的胜率。人类评估者也表示赞同,在 66.4% 的比较中更偏向 VISTA 的输出。