RAGDoll: Efficient Offloading-based Online RAG System on a Single GPU
基本信息
| 属性 | 内容 |
|---|---|
| 标题 | RAGDoll: Efficient Offloading-based Online RAG System on a Single GPU |
| 作者 | Weiping Yu, Ningyi Liao, Siqiang Luo, Junfeng Liu |
| 机构 | Nanyang Technological University |
| 来源 | 2025 arXiv: 2504.15302v1 |
| 总结 | 针对单张消费级 GPU 的资源受限场景,通过解耦检索与生成流水线、分层内存联合调度及自适应批处理,实现高效的 RAG 在线服务。 |
摘要
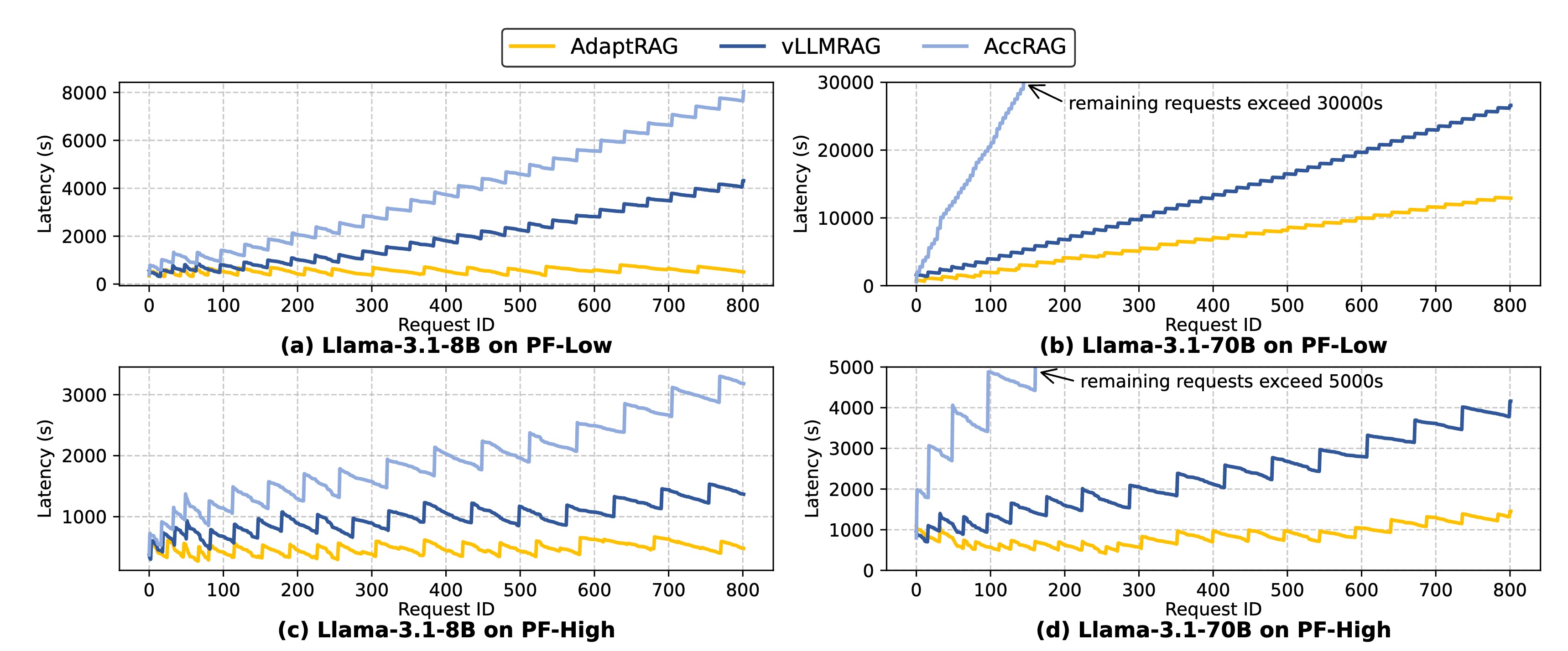
检索增强生成(RAG)通过引入相关外部知识提高了大语言模型(LLM)的生成质量。然而,由于内存有限以及模型和知识库规模的不断增加,在消费级平台上部署 RAG 极具挑战性。本文介绍了 RAGDOLL,这是一个专为资源受限平台设计的资源高效型、自适应 RAG 服务系统。RAGDOLL 基于一个核心洞察:RAG 的检索和 LLM 生成阶段具有不同的计算和内存需求,传统的串行工作流会导致大量的空闲时间和资源利用率低下。基于此,RAGDOLL 将检索和生成解耦为 并行流水线(parallel pipelines),并结合 联合内存放置(joint memory placement) 和 动态批处理调度(dynamic batch scheduling) 策略,以优化跨不同硬件设备和工作负载的资源使用。大量实验表明,RAGDOLL 能有效适应各种硬件配置和 LLM 规模,与基于 vLLM 的串行 RAG 系统相比,平均延迟实现了高达3.6 倍的加速。